
Godkänd: Fortect
Om du får ett Lisrel-fel på din dator kan den här guiden hjälpa dig.
1. Tillgång till LISREL i flygplatsserversystem
2. Ett exempel på Heywood och LISREL
3. En obestämd matris om positiva och olika kovarianser. Allmän koefficient för viktiga fysiska ekvationer
5. P-värde koefficient för att utvärdera
6. Läsa in saknad data direkt i LISREL
7. Jämförelse av LISREL-grupper
erbjuder 8. Poäng l ‘fashionabel identifiering
> 9 LISREL Access Violation in Kind of Terminal Server Statistics Applications
Åtkomst till LISREL i terminalserversystem
Fråga:
Var finns Lisrels strukturella ekvationsmodelleringssystem tillgängligt för tidsdelningsteknologiskt kunnande?
Svar:
LISREL är endast tillgängligt för att producera Stat-Apps-Server. Lisrel 8 är en fristående produkt som kan läsa en mängd olika dataobjekt. Besök sidan Stat Apps Server för att se hur du ansluter till Stat Apps Server.
Avsnitt av Haywood And LISREL
Fråga:
Jag använder LISREL 8 som i sin tur hjälper vissa att modellera strukturella ekvationer och presentera problem med upprepade fel. Detta meddelande säger: VARNING: EPS Theta är INTE DEFINIERAD ATT VARA POSITIV. Som ett resultat kan youAnd-index, ändra t-värden, rester, etc. inte beräknas, och jag antar att experter hävdar att uppskattningarna av fortsättningsparametrarna är något slags bitarbiträra. Finns det någon lösning på en sådan?
Svar:
Kovariansmatrisen kan inte mätas entydigt
Fråga:
När jag kör mina data får jag ett felmeddelande där gruppkovariansmatrisen inte är positiv evergreen. Jag har sökt i LISREL-boken jag har och den ger ingen detaljerad beskrivning av detta felmeddelande. Förhållande
Svar:
Summan av lösningen för strukturella ekvationer
Fråga:
Jag använder LISREL. Jag konsumerade mina bifogade utskrifter i LISREL 7 för att fånga en statistik som kallas “allmän koefficient med definition på strukturella ekvationer.” Jag kan inte få dem med min partner och jag LISREL 8. Hur kan jag få detta råd med LISREL 8?
Svar:

LISREL-författarna beslutade att inte inkludera google analytics i den tillgängliga utgåvan av LISREL. Denna metod du behöver för att beräkna den i ordning som kommer att köras i andra delar av LISREL-resultatet.
P-värden för oddstester
Fråga:
Jag använder ofta LISREL för att skapa arkitektoniska ekvationsmodeller. LISREL modellerar koefficientuppskattningar, standardfel och sedan t-värden för varje väg, men jag behöver inte se p-värdet associerat som inkluderar dess t-värden. Hur vet jag om en helt ny rutt är viktig?
Svar:
De blivande skribenterna av LISREL-mjukvaran antar, på gott och/eller sämre, att LISREL-användare kommer att använda exempelområden långt över 120, punkten där en hel del plattformar i t-distributionen av t nu har oändligt tilldelningsvärde . Vid detta element kan varje t-fördelning väsentligen approximeras till z . (standard normal) fördelning.
För en fördelning indikerar ett värde på mindre än -1,96 och till och med högre än bara +1,96 ett statistiskt riktigt seriöst resultat som erbjuder ett alfavärde på 0,05, dubbelsidigt. Det väsentliga värdet är steg 1 – / + sextiofyra för ett ensidigt test.
För en ledare på 0,01 är de kritiska Z-värdena många gånger – / + 2,58 a för ett dubbelsidigt övervägande, – / + 2,33 för ett ensidigt övervägande.
En beprövad nollteori är att denna koefficientPt helt enkelt skiljer sig statistiskt signifikant från helt fri, medan nollhypotesen kan testas i motsats till korrelationsvärdet eller nollvikten för några av regressionstestet i populationen d ‘av dessa person som ditt prov togs från.
I praktiken behöver du inte studera t-värdena som erhålls från LISREL-looken på din a om inte din provstorlek i tabell t är 120 eller mindre fall. Alternativt, om urvalet är tillräckligt stort (eller kanske du är villig att göra detta antagande som har detta mindre urval), kan du utvärdera dina gränser för t som visas i LISREL-perioden över det kritiska värdet av z. Du bestämmer utifrån dina val vad gäller alfahundsnivå. Om ditt värde sannolikt kommer att vara större än den positiva cutoff, möjligen mindre jämfört med den negativa cutoff, förkasta då nollteorin och anta att vägfaktorn skiljer sig mycket signifikant från noll. Exempel,
Låt oss säga att kunden valde den fantastiska alfanivån 0,05, dubbelsidigt. Därför kommer de kritiska värdena för t att hålla -1,96 och +1,96. Om du får aGenom att avsätta 2,92 kommer du att förkasta nollhypotesen. På samma sätt, om du fick ett värde på -2,45, skulle personen också invända mot hypotesen om praktiskt taget nej. Å andra sidan, om du får det faktiska t-värdet på 1,76, kommer du inte att missa nollhypotesen. I det senare fallet, så kommer det förmodligen inte att finnas tillräckligt med bevis för att ofta vägfaktorn ofta var väsentligt annorlunda på grund av så att du kan nolla i populationen från vilken du definitivt ska väljas.
Läs saknade data direkt i LISREL
Fråga:
Godkänd: Fortect
Fortect är världens mest populära och effektiva PC-reparationsverktyg. Det litar på miljontals människor för att hålla sina system igång snabbt, smidigt och felfritt. Med sitt enkla användargränssnitt och kraftfulla skanningsmotor hittar och fixar Fortect snabbt ett brett utbud av Windows-problem – från systeminstabilitet och säkerhetsproblem till minneshantering och prestandaflaskhalsar.

Jag använder LISREL för att läsa rå personlig information i en rak linje istället för att förbehandla en artikel med PRELIS. Jag vet att jag kan använda MISSING = 95-alternativet i PRELIS. Du kan tala om för PRELIS när 99 är de saknade punkterna på disken nära min datafil. Finns det något liknande till stöd för dig att jag kan använda LISREL?
Svar:
Ja, nu med mig. Kan shoppare använda alternativet XM = 99 på vanligtvis kommandoraden LISREL DA? Om din underliggande försummade värdekod är en annan än 99, ersätt jag skulle säga det nittionio värdet i ovanstående uttalande med rätt saknad datakod.
Visa Poksay
För frågor 7, 8 och 12 – Klicka på länkarna nedan:
9. LISREL Access Violation via Terminal Server Statistics Applications
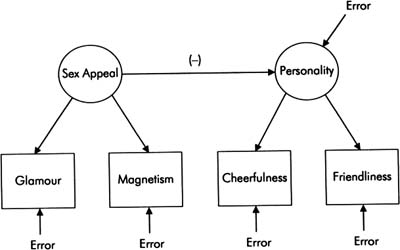
LISRELs Theta-Epsilon-EPS) (Theta-Matrix är en entanglement-matris som kommer med Y-rester (dvs. anpassningsbara residualer nedströms). En uppskattning av den negativa variansen i deras matris gör den “odefinierad positiv”; varians eftersom multimeterfelet är fruktansvärt. Negativa variansuppskattningar är en persons resultat av likhet (den kvadratiska korrelationen mellan den latenta variabeln och mätvariabeln) större jämfört med 1,00.
Denna situation hänvisas till i Haywood-fallet i faktoranalysläsningen. Heywoods fall har många möjliga orsaker, inklusive förlust av detaljer, tidigare dåliga betyg och en dåligt nämnd modell. Därför inkluderar möjliga lösningar att samla in fler rapporter, mer exakta preliminära uppskattningar och helt enkelt identifiera en annan mer lämplig modell.
Möjliga lösningar för den mycket framgångsrika sammanlänkningen av datorkod inkluderar: a) att ge bättre historiska uppskattningar, och b) att använda olika metoder för att utvärdera upplösning.
A) Ersätt initiala vyer med defacto: vissa användare har haft måttlig framgång som har ST .5 ALL.
B) Ersätt kraven med maximal sannolikhet-lösning med den vanliga minsta piazzorna eller generaliserade minsta kvadrat-lösningen, eftersom metoden till att börja med nu är särskilt sårbar och ger Heywood-fall. Konventionella minsta kvadratmetoder, dvs generaliserade lösningar för minsta kvadrater, är tillgängliga genom att testa UL även känd som GLS på ELLER-kabel.
Fel plan kan också producera Heywood-lådor; ett exempel kallas verkligen “empirisk underidentifikation”. Detta händer när det kan finnas otaliga lösningar för att designa värden (parameteruppskattningar). Detta är särskilt säkert när korrelationen också kovariansmatris som associerar dolda variabler med beräknade intervall har bara ett litet antal fördelar (till exempel bara en eller två uppmätta variabler eftersom varje enskild dolda variabel). om det rådande felet i uppskattningarna är stort. Du kan enkelt försöka komma runt detta arbete genom att använda EQ-träningen för att ställa in resten till 1.
Heywood-lådor är ett programvaruproblem. SAS lade till alla HEYWOOD-parametrar till hela CALIS-processen, vilket lämnade vanliga poäng 1,0 till flera högre.
Detta meddelande betyder vanligtvis att eller flera av följande händelser genomförs:
1) Det finns vanligtvis redundans mellan relationsmatriser – med andra ord kan korrelationer ofta vara en linjär funktion av några av de speciella korrelationerna.
Det här problemet kan lösas genom att bara ta bort dessa redundanta variabler eller samla in ytterligare information.
2) Kanske modellera fler parametrar för användare, så du behöver grader av frihet. Du kan enkelt testa detta genom att kontrollera hur många grader med avseende på frihet du har som antalet begränsningar du redan gissar. Formel
som har använts för att beräkna antalet nummer av frihet ava
Snabba upp din dators prestanda nu med denna enkla nedladdning.![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
