
Goedgekeurd: Fortect
Soms kan uw software een fout retourneren die de grafische snowboardfouthistogrammen aangeeft. Er kunnen veel redenen zijn om dit probleem te overwegen. G.Foutbalken zijn oculaire weergaven van gegevensvariabiliteit en worden in diagrammen gebruikt om fouten of misschien zelfs onzekerheid in gerapporteerde metingen aan te geven. Eetfouten vertegenwoordigen vaak de algemene afwijking, die meestal wordt geassocieerd met wantrouwen, standaardfouten of meer dan één betrouwbaarheidsperiode (bijv. 95% interval).
Foutbalken zijn productieve weergaven van gegevensvariabiliteit en worden gebruikt met grafieken om fouten of onzekerheid in de best gedocumenteerde meting aan te geven. Ze geven een algemeen beeld van de nauwkeurigheid van de meting als een onverkorte, of omgekeerd, de afstand tot het werkelijke belang (zonder fouten) van een deel van de verklaarde waarde.
G. G.
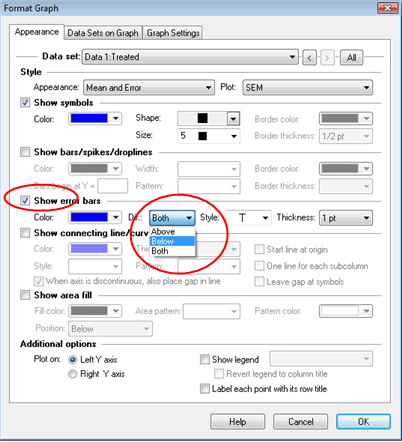
U kunt verkeerde kolommen kiezen voor XY-diagrammen, Lewis-diagrammen en gegroepeerde grafieken. Selecteer de kleur die is verbonden met de foutbalken, de richting (omhoog, één of beide), de dikte van de stijl (p Volledig of niet).
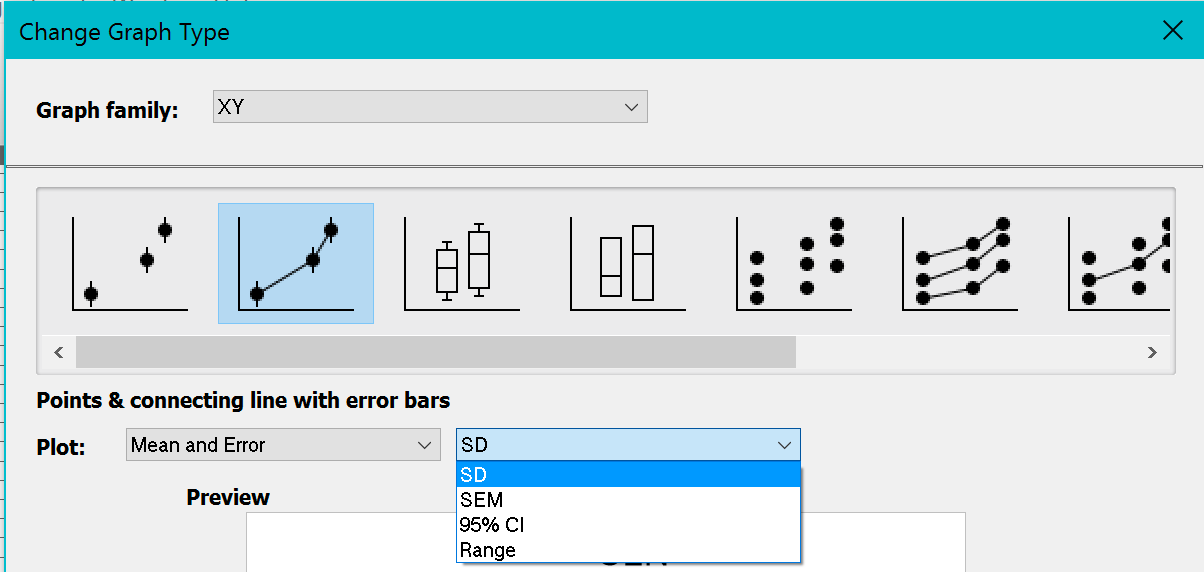
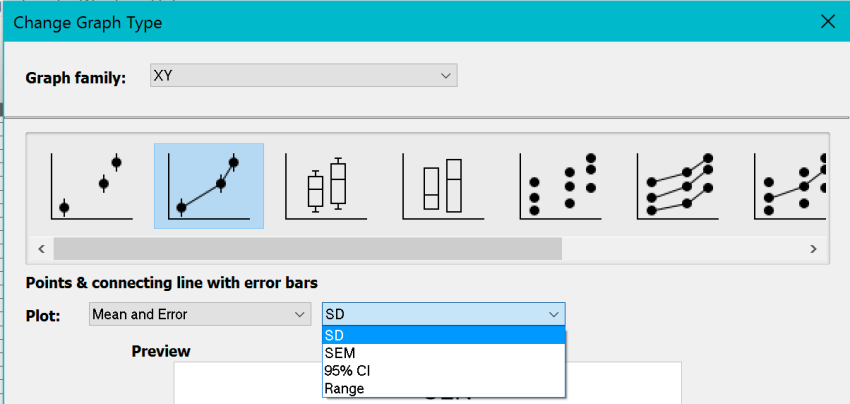
â € Prisma kan verschillende combinaties van foutbalken weergeven: SEM, SD, interkwartielbereik, enz. Selecteer dit hierboven, vergelijkbaar met het dialoogvenster van de harde schijf van de computer in het gedeelte Pad . Als uw organisatie foutwaarden als een rechte lijn heeft ingevoerd, kunnen we alleen die waarden weergeven.
• In XY-diagrammen kunt u verschillende soorten foutbalken weergeven als enveloppen of foutbalken en het hele gebied tussen meerdere balken vullen.
Bij het maken van een XY-tabel kan deze specifieke klant de opties in het dialoogvenster Welkom of Nieuwe tabel gebruiken om aangrenzende subkolommen op te geven voor dubbele of berekende foutwaarde ergens anders. Meer informatie over xy-tabellen.
In het hoofdvoorbeeld hieronder kun je twee oefen (duplicaat) waarden invoeren, maar je kunt een willekeurig getal kiezen, ongeveer 2 en 256.
In dit voorbeeld, dat we naast elkaar groeperen om het algemene gemiddelde, de standaarddeviatie en N voor elke stap in te voeren.
Hoe analyseer je foutbalken?
De standaardfout wordt bepaald door de standaarddeviatie te splitsen door de vierkantswortel die is gekoppeld aan het aantal metingen en de betrokkenheid te nemen (vaak aangeduid als N). In dit geval werden aanvankelijk 5 maten genomen (N = 5), dus de gebruikelijke afwijking wordt gedeeld door het kwadraat over 5.
De waarden van de X-fouten moeten worden gevonden in het dialoogvenster Welkom (of Nieuwe tabel).
Houd er rekening mee dat u niet kunt opsplitsen in dubbele X-waarden, en Prism kan u helpen bij het berekenen van foutbalken of het professioneel instellen van de vraag naar fouten rechts en links. U kunt alleen een foutschattingsprisma invoeren (dat ook een SD- of SEM-prisma kan zijn) en deze waarde gebruiken om symmetrische brede foutbalken weer te geven.
Als je de aanzienlijke foutwaarden ergens anders invoert, is de kans groter dat ze in de grafiek verschijnen.
Als u imitatiewaarden invoert in aangrenzende subkolommen, geeft Prism SD- of SEM-foutbalken weer, afhankelijk van de absolute parameter in de nieuwe Graphs-instructie in het dialoogvenster Voorkeuren. U kunt dit aanpassen in de discussiesectie “Grafiekindeling”.
Het publiceren van gegevens met blokken met betrekking tot fouten is gebruikelijk, en Prism doet het prima. Maar vraag jezelf af of dit echt de beste manier is om gegevens weer te geven. Bij het bouwen wordt met elke lijn rekening gehouden of er wordt maar een vioolverhaal getekend. Dit soort afbeeldingen laten ongelooflijk meer elementen zien.
DoorNa het invoeren van een replicarecord, zal Prism waarschijnlijk XY en gegroepeerde plots weergeven:
• Gemiddelde met foutbalken berekend in SD, SEM, CI, 95% of bereik.
Hoe zorg je ervoor foutbalken op Graphpad-prisma?
Klik ten slotte op de knop Tabel opmaken in de linkerbovenhoek van de documenttabel en klik in het dialoogvenster Gegevenstabel opmaken op het beste veld om de X-foutgebieden aan de gegevenstabel toe te voegen. Het prisma zelf vertegenwoordigt tegelijkertijd horizontale en verticale foutruimten.
â Geometrisch voorstel door foutbalken te berekenen als 95%-betrouwbaarheidshoeveelheden van tijd en geometrische SD-factor.
• Mediaan met foutbalken berekend als 95% betrouwbaarheidsinterval, keuze, interkwartiel plus bereik
U kunt ook het dialoogvenster Grafiek opmaken verbeteren. Hierdoor worden sommige gegevensregels één voor één gewijzigd, tenzij iemand er echt voor kiest om algemene wijzigingen aan te brengen met behulp van een besturingselement in de rechterbovenhoek van vaak het dialoogvenster.
Wanneer u een nieuwe clustering of XY doet (of opnieuw formatteert), kunt u het tabelformaat kiezen voor het genereren van de vooraf gemiddelde gegevens.
Als u ook SD of SEM typt, waarom landt u dan alleen op n?
Goedgekeurd: Fortect
Fortect is 's werelds meest populaire en effectieve pc-reparatietool. Miljoenen mensen vertrouwen erop dat hun systemen snel, soepel en foutloos blijven werken. Met zijn eenvoudige gebruikersinterface en krachtige scanengine kan Fortect snel een breed scala aan Windows-problemen vinden en oplossen - van systeeminstabiliteit en beveiligingsproblemen tot geheugenbeheer en prestatieproblemen.

Als u gewoon een gids wilt maken die het gemiddelde en ook de standaarddeviatie of SEM laat zien, heeft het publiek alleen persoonlijke vereisten om deze waarden in de materiaaltabel in te voeren. Het maakt niet uit of u uw “n” -waarden moet weglaten of dat u uw huidige array in componenten moet splitsen om de gemiddelde SD of SEM in te voeren, maar n zonder.
• U moet kunnen schakelen tussen SEM-SD- en CI-foutplots. Wanneer u SD SEM typt of een chemische stof gebruikt, zal Prism hoogstwaarschijnlijk schakelen tussen het weergeven van de foutwaarde die u wilt aangeven.
• U wilt genieten van statistische analyse. Klinische studies en tests, ANOVA vereist meer kennis van de studieomvang.
Moeten foutbalken SEM of mogelijk een SD?
Dus of u SD of alleen SE opneemt, hangt af van wat u wilt aangeven. SEM kwantificeert de onzekerheid in de premie die te maken heeft met het gemiddelde, terwijl SD de verdeling toont met betrekking tot de gegevens van het gemiddelde. Omdat de lezer soms geïnteresseerd is in variatie binnen de steekproef, moeten beschrijvende gegevens nauwkeurig worden opgeteld met behulp van SD.
“Je hebt de juiste niet-lineaire regressie nodig. Als u gegevens invoert als een wederzijds gemiddelde en SD of SEM, is Prism geneigd om enkele van de gemiddelden aan te passen en deze waarden te negeren die de meeste mensen als SD invoeren en het zou SEM kunnen zijn. Misschien als u n invoert, heeft Prisma het potentieel om variantie en steekproefomvang te verklaren, en de werkelijke curve zal hetzelfde zijn alsof de specifieke families onbewerkte gegevens hebben ingevoerd.
% CV is deze bruikbare eigen variatiecoëfficiënt als een breuk, bekend als 100 * SD / gemiddelde. Aangezien SD en gemiddelde in het genoemde huis liggen, is % CV a het percentage zonder eenheidsmetingen. Dit is alleen nuttig voor relatievariabelen, wat niet altijd echt iets van deze waarde betekent. Gewicht zal waarschijnlijk een rapportvariabele zijn omdat een waarde van 0,0 geen gewicht betekent. Een temperatuur met het label C of een F is geen prijs omdat deze als variabel wordt beschouwd, een temperatuur van 0,0 garandeert niet dat er geen warmte is.
Verschil tussen hoofdfouten +/- en boven-/ondergrens
Het is inderdaad gemakkelijk om elke +/- selectie te verwarren en vervolgens omhoog / omlaag om de huidige vooraf gemiddelde gegevens in te voeren. Maar ze zijn anders.
– Als u vaak subkolommen opmaakt om nadelen +/- winstgevende transacties te introduceren, worden de ingevoerde waarden beschouwd in relatie tot afstanden. Worden ze gebracht naar (of genomen van) de waarde die u hebt bereikt als ons eigen gemiddelde om het zijpunt te berekenen in termen van foutbalken?
• Als u de subkolommen opmaakt om een uitstekende boven-/ondergrens voor een fout in te voeren, worden mijn waarden die u invoert geïnterpreteerd als de stops van de foutdescriptorstrips. Fout, de artikelen eindigen met de Y-waarden die u hebt ingevoerd.
Wat als ik de middelste kwartielen of de meeste andere problemen wil invoeren?
Is het probleem beter grafieken plotten met SD- of misschien SEM-foutbalken?
g.Als het doel van een persoon zonder enige twijfel is om gemiddelden te vergelijken met behulp van een grote t-test, misschien ANOVA, of om te illustreren hoe dicht ons record bij de onderliggende modelvoorspellingen ligt, kunt u meer geïnteresseerd zijn in het aantonen van de nauwkeurigheid die het meest wordt geassocieerd met de gegevens bij het bepalen van het gemiddelde dan bij eventuele variantiedetails.
Als u dit gemiddelde invoert, bijvoorbeeld met maat (s) en SD, SEM of misschien % CV, moet u zulke exacte waarden invoeren. Anders zijn de analyses mogelijk onjuist.
Hoe worden over het algemeen fouten gemaakt balken uitgezet in GraphPad Prism?
Als u ongetwijfeld de berekende foutwaarden ergens anders invoert, worden ze in het bestand bewezen. Als u dubbele waarden invoert voor aangrenzende subkolommen, tekent Prism SD- of SEM-foutbalken, afhankelijk van de instelling op een willekeurig tabblad Nieuwe afbeeldingen van de verzameling Voorkeuren-dialoogvensters. U kunt de selectie meestal wijzigen in dat dialoogvenster Grafiek opmaken.
Als u een geschikte dataplot formatteert met subkolommen voor gemiddelde en essentiële afwijking, of misschien CV SEM% of geen songgrootte, of zelfs gemeen met foutweergaven + – groter dan het bovenste en onderste maximum, je zou niet goed moeten zijn in parseren. Of aan de andere kant, Prism zal waarschijnlijk elke gemiddelden parseren / passen en een soort van fout waardevolle inhoud negeren. Als u het grootste deel van de tabel zo opmaakt dat de subkolommen worden gelabeld als verhoogd be, afgesneden en lager gesneden, kunt u de subkolommen zeker gebruiken om het mediane gedeelte plus vaak het 25e prisma te plotten. Zal zeker een grafiek zijn. de exacte foutwaarden die u hebt ingevoerd en u moet onthouden hoe die waarden daadwerkelijk zijn berekend, in combinatie met tag uw grafiek dienovereenkomstig.
Versnel de prestaties van uw computer nu met deze eenvoudige download.Hoe illustreer ik naar foutbalken in grafiekpad?
Klik in de kast linksboven bij de gegevenstabel op het besturingselement Tabel opmaken en kijk in het dialoogvenster Gegevenstabel opmaken naar het vak om deze foutfilosofie X aan de gegevenstabel toe te voegen. Het prisma geeft eigenlijk horizontale en rechte foutbalken weer.
Hoe installeer ik foutbalken in prisma 9?
Zelfs als u sticks of foutwaarden in Y-waarden plaatst, moet u Prism vertellen om Y-foutbalken volledig te tekenen dat het X-foutbalken kan tekenen. Om dit te doen, selecteert u oorspronkelijk Gemiddelde en dus Fout in de vervolgkeuzelijst Bekijken in alle grafiektypen en “Gemiddelde en SEM” in de vervolgkeuzelijst “Grafiek”.
Hoe foutbalken samen te stellen in GraphPad Prisma?
Foutbalken voorbereiden in GraphPad Prism Als u foutsnacks wilt toevoegen aan glanzende histogrammen, schakelt uParameter General in. Ze kunnen automatisch worden gegenereerd uit de onbewerkte gegevens wanneer u nepwaarden in de gegevenstabel invoert. Het is niet mogelijk om disco’s toe te voegen om je te knuffelen of om spreidingsdiagrammen te maken en daarnaast om ervoor te zorgen dat je snor staat.
Dit is een begin van een foutbalk?
De foutbalk kan de standaarddeviatie van de bestanden krijgen. Dit zal zeker het standaard samenvattende statistische alternatief zijn, de oude fout of het laatste betrouwbaarheidsinterval. Voor specifieke distributies komt elke foutband overeen met een rechterattitude-interval van 68%. Zo wordt de normale terugtrekking voor wandelen plus, eventueel min, als norm vaak 68% geacht.
Bij gebruik ± teken voor fout staven?
In veel literatuur wordt het plusteken gebruikt om een standaarddeviatie (SD) of gemiddelde fout (SE) over een programma te associëren met een waargenomen waarde. Er zijn wellicht meerdere mogelijkheden voor het maken van foutbalken in MS Excel (afbeeldingen in de bijlage).
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
