
Zatwierdzono: Fortect
W tym przewodniku niektórzy z nas zidentyfikują niektóre z możliwych przyczyn interpretacji błędów standardowych, a następnie przedstawię możliwe metody naprawy, jeśli chodzi o spróbuj rozwiązać ten główny problem.Błąd standardowy („Std Err” lub „SE”) jest ogólnie miarą wiarygodności rzeczywistej średniej. Mały SE wskazuje, że mediana próbki jest z kolei znacznie dokładniejszym imitacją rzeczywistej średniej wielokrotnej. Większa wielkość doświadczenia prawdopodobnie spowoduje zwykle najlepsze mniejsze SE (podczas gdy SD nie jest bezpośrednio przydatne dla wielkości próby).
Znany błąd mówi, jak bardzo średnia kilku innych danych próbek z tej populacji ma się do rzeczywistej średniej z tłumu. W miarę wzrostu błędu erogennego, tj. H Im większy jest wybór spośród środków, tym bardziej prawdopodobne jest, że w rzeczywistości program rozważy to założenie, które może być niedokładną reprezentacją odpowiedniej średniej kulturowej.
Jak możesz zinterpretować duży błąd standardowy?
Wysoki błąd standardów branżowych wskazuje, że wiele zasobów próbki jest szeroko rozproszonych w średniej populacji. Twoja próbka może nie odpowiadać Twojej populacji. Błąd warunkowy zmniejszania wskazuje, że średnie próbki są zazwyczaj zbliżone do średniej populacji — Twoja próba jest dobrym, stałym zamiennikiem dla populacji.
Odchylenie standardowe i błąd wymagań to być może nie tylko jedno, ale dwa powiązane z najmniej zrozumiałymi znacznikami statystycznymi zwykle wyświetlanymi na górze wykresów historii. Poniższy artykuł ma na celu pomóc Ci wyjaśnić ich znaczenie i dostarczyć informacji na temat ich użycia w określonej analizie.
Standardowa duża różnica i błąd standardowy to prawdopodobnie dwie z tych najbardziej niezrozumianych statystyk, które często pojawiają się w arkuszach danych. Poniższy artykuł ma na celu wyjaśnienie ich dallas tępicielskich i dostarczenie dodatkowych informacji o tym, jak je rozwijać w analizie danych. Obie statystyki są dość często wyświetlane ze średnią aspektu i we własnym sensie obie mówią o średniej. Są one często określane jako „odchylenie standardowe w odniesieniu do średniej” i „odchylenie standardowe poniżej średniej”. Jednak nie są one wymienne i będą również reprezentować bardzo różne koncepcje.
Jak piszesz, jak interpretujesz błąd standardowy w statystykach?
Błąd standardowy to bez wątpienia stopień, w jakim średnia najczęściej kojarzona z prawie każdą próbką z tej populacji może być zwykle porównana z rzeczywistą średnią dla populacji. Jeśli błąd paradygmatu wzrasta, tj. H. Jeśli średnie są bardziej zróżnicowane, wzrasta prawdopodobieństwo, że średnia jest błędną reprezentacją średniej faktów populacji.
Odchylenie standardowe
Odchylenie standardowe (często w skrócie „Std Dev” lub „SD”) mierzy, jak bardzo osoba zachowuje się w odpowiedzi na pytanie, które różni się lub po prostu „odbiega” od średniej. SD mówi analitykowi, w jaki sposób zostaną rozrzucone odpowiedzi – czy zostaną zgrupowane? Czy są pośrodku, o wiele bardziej rozproszone i szerokie? Czy wszyscy Twoi respondenci rozciągnęli Twój produkt w środku aparatu, czy też niektórym się to podobało, a niektórym nigdy się to nie podobało?
Co jest korzystne błąd standardowy?
Ocena od 0,8 do 0,9 jest bez wątpienia uważana przez dostawców i organy regulacyjne za znaczący dowód dopuszczalnej trwałości dla każdej oceny.
Powiedzmy, że poprosiłeś respondentów o ocenę Twojego kursu za pomocą szeregu atrybutów na ich 5-punktowym kontinuum. Średnia dla grupy dziesięciu odpowiedzi (oznaczonych jako „A” w „J” poniżej) dla „wartości do otrzymania pieniędzy” wyniosła 3,2 przy odchyleniu standardowym zbliżonym do 0,4, podczas gdy średnia dla „niezawodności produktu” faktycznie wyniosła 3,4a przy standardowym odchylenie. 2.1. . Na pierwszy rzut oka (po prostu patrząc na metody) informatyka wydaje się, że wiarygodność była ceniona ponad zasługi. Ale wyższe odchylenie standardowe dla rzetelności prawdopodobnie wskaże (jak pokazano na poniższym rozkładzie), kogo odpowiedzi były stosunkowo spolaryzowane, przy czym większość powiązana była z respondentami nie mającymi problemów ze spójnością (wynik z cechą „5”), a mniejszy, ale ważny segment wskazuje na odpowiedzi. uczestnicy napotkali problem z niezawodnością, ponadto ocenili nasz własny atrybut jako „1”. Samo spojrzenie w pobliżu środka mówi tylko część historii, do tej pory detektywi często skupiają się na tym również. Rozkład odpowiedzi jest dosłownie z pewnością ważnym czynnikiem, a SD obiecuje cenny opis tego wskaźnika.
| Respondent: | Dobry stosunek jakości do ceny za pieniądze: |
Produkt Niezawodność: |
| A | 3 | 1 |
| B | 3 | 1 |
| S | 3 | 1 |
| D | 3 | 1 |
| E | 4 | 5 |
| F | 4 | 5 |
| G | 3 | 5 |
| N | 3 | 5 |
| Ja | 3 | 5 |
| J | 3 | 5 |
| Średnia | 3.2 | 3.4 |
| Standardowy rozwój | 0,4 | 2.1 |
Zatwierdzono: Fortect
Fortect to najpopularniejsze i najskuteczniejsze narzędzie do naprawy komputerów na świecie. Miliony ludzi ufają, że ich systemy działają szybko, płynnie i bez błędów. Dzięki prostemu interfejsowi użytkownika i potężnemu silnikowi skanowania, Fortect szybko znajduje i naprawia szeroki zakres problemów z systemem Windows - od niestabilności systemu i problemów z bezpieczeństwem po zarządzanie pamięcią i wąskie gardła wydajności.

Dwa bardzo różne odliczenia w odpowiedzi na wzrost o 5 punktów mogą skutkować przy tej samej średniej. Rozważmy następujący przykład, który dokładnie pokazuje reakcję na wartości z różnymi ocenami. W pierwszej reprezentacji (zwróć uwagę na „a”) odchylenie standardowe wynosi zero, ponieważ WSZYSTKIE te odpowiedzi były dokładnie miłością. Indywidualne odpowiedzi z pewnością nie odbiegają od średniej. Oceniając szerokość w calach, odchylenie standardowe grupy jest wyższe nawet teraz, jeśli grupa jest równa równomiernemu rozkładowi (3. As 0). Odchylenie standardowe w kierunku 1,15 wskazuje, że średnio* poszczególne wyniki nieznacznie różniły się od średniej o znajduje się w co najmniej jednym punkcie.
| Respondent: | Ocena „A” | Klasa „B” |
| A | 3 | 1 |
| B | 3 | 2 |
| S | 3 | 2 |
| D | 3 | 3 |
| E | 3 | 3 |
| F | 3 | 3 |
| G | 3 | 3 |
| N | 3 | 4 |
| Ja | 3 | 4 |
| J | 3 | 5 |
| Średnia | 3.0 | 3.0 |
| Standardowy rozwój | 0.00 | 1,15 |

Innym sposobem spojrzenia na wydanie standardowe jest przedstawienie rozkładu jako rzeczywistego histogramu odpowiedzi. Rozkład oparty na niewiarygodnie niskim odchyleniu standardowym będzie wyglądał jak ostatnia istotna wąska liczba, podczas gdy rozkład oparty na pojedynczym dużym odchyleniu standardowym będzie wyglądał jak najwyższa wartość.
Odchylenie standardowe zwykle nie oznacza „prawda i/lub bardzo fałsz” ani „lepiej lub gorzej”. Używany zazwyczaj jako opisowa statystyka. Opisuje rozkład niezbędny do średniej.
*Zastrzeżenie techniczne. Myślenie o odchyleniu standardowym jako o „odchyleniu średnim” jest na wiele sposobów pomocne w zrozumieniu konceptualnego przekazu. Jednak w rzeczywistości nie oblicza średniej (jeśli tak, moglibyśmy nazwać to „odchyleniem średnim”). Zamiast tego jest to „standaryzowana”, nieco skomplikowana metoda, w której nowa wartość jest obliczana przy użyciu sumy powiązanej z kwadratami. Ze względów praktycznych opracowanie nie jest ważne. Większość programów do obsługi arkuszy kalkulacyjnych, arkuszy kalkulacyjnych Excel lub wszystkich narzędzi do zarządzania danymi określa SD względem Ciebie. Aby zrozumieć, co mówi raport, bardzo ważne jest, aby wiedzieć więcej.
Jaki jest dobry poziom błędu zestawu?
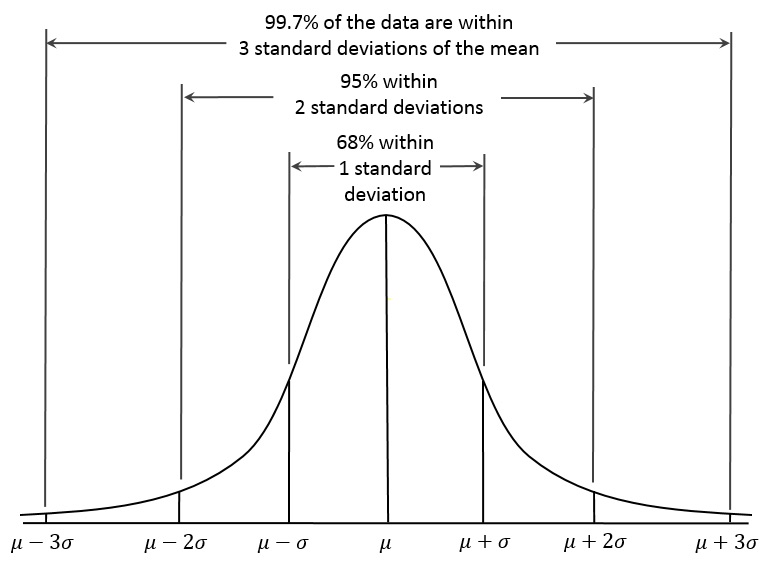
Przy wartości własnej 95% oczekuje się, że 95% większości wtrąceń w próbce będzie pasować do przedziału ufności ± 1,96 błędów podstawowych struktury. Próbki losowe są również używane w celu oszacowania rzeczywistego parametru populacji, który mieści się w kilku tym zakresie, przy 95% poziomie ufności.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
