
Se tutti ricevono un messaggio di errore della rete genetica, la guida per i visitatori di oggi è stata creata per aiutarti.
Approvato: Fortect
Riprendi
Diversi studi si sono concentrati sull’impatto più importante delle tecniche forestali casuali a causa delle sue prestazioni superiori. Alcuni di questi metodi di inferenza hanno inoltre una solida capacità di analizzare lo spettacolo del tempo e di determinare i dati di espressione genica. Tuttavia, sono utili solo per classificare tutti i relativi regolamenti collegando gli aspetti della fiducia. Nessuno di loro è stato in grado di scoprire le regole specifiche specifiche che in realtà influenzano il gene più spesso associato all’interesse. In questo studio, i membri del nostro staff propongono questo metodo per rimuovere i piani candidati poco promettenti, combinando essenzialmente l’inferenza casuale della foresta con una manciata di metodi di selezione delle caratteristiche. Come componente per il rilevamento di molte regole errate, la nostra piattaforma utilizza gli elenchi delle procedure di selezione delle funzionalità per abbinare i valori di affidamento dei requisiti normativi quasi impliciti che sono stati calcolati onestamente utilizzando metodi basati sull’inferenza. Esperimenti numerici, che hanno evidenziato che l’applicazione combinata con trucchi di selezione delle caratteristiche ha migliorato l’uso dell’inferenza casuale della foresta di 98 esperimenti su 100 eseguiti su problemi artificiali personali. Tuttavia, il miglioramento è complessivamente limitato poiché il nostro metodo è stato riconosciuto collettivamente e ha rimosso non più del 19% dei requisiti normativi interamente possibili. L’applicazione combinata, oltre ad assisterti nel processo di selezione delle funzionalità, aiuta anche a ottenere costi di calcolo. Sebbene una svolta più ampia con un costo computazionale ridotto sarebbe l’ideale, non vediamo alcun ostacolo alla nostra ricerca, poiché il nostro obiettivo è davvero quello di estrarre quante più informazioni utili disponibili dalla quantità limitata di statistiche sulle frasi genetiche. FANTASMA5,
Parole chiave: espressione genica, selezione dei caratteri, foresta inutile, derivazione della rete genetica
1. Presentazione
La risposta dinamica dell’espressione genica determinerà una varietà di funzioni cellulari. La nostra comprensione insieme alle possibilità biologiche richiede lo studio di versioni complesse della regolazione genica, poiché la regolazione tra i geni stessi e determina come i geni vengono espressi. Un incontro più sicuro sviluppato per l’analisi della regola genica inclusiva è la localizzazione genetica. In un piano di rete genetica, la regolazione generale tra i geni viene dedotta al di fuori dei dati di espressione genica misurati con tecnica biologica simile a microarray a RNA-Seq utilizzando sequenziatori di fette. La prossima età e molto altro ancora. I modelli di team derivati possono idealmente servire come utilità per aiutare i biologi a creare ipotesi e pianificare questi esperimenti. Pertanto, molti ricercatori si sono interessati all’influenza delle reti genetiche.
Sono stati proposti numerosi metodi per la derivazione di pacchetti genetici (Larrañaga et al., 2006; Meyer et al., 2008; Chou e Voit, 2009; Hecker et., 2009; Matos de Simoes e Emmert-Streib , 2012; Emmert-Streib et al., 2012; Glass et al., 2013). Tra questi, i metodi di esposizione casuale delle foreste promettono prestazioni davvero buone (Huynh-Thu et al., 2010; Maduranga et ing., 2013; Petralia et., 2015; Huynh-Thu e Geurts, 2018; And kimura al., 2019). … Alcuni di ciascuno di questi modelli di inferenza possono anche confrontare sia gli episodi temporali che i dati di espressione genica statica (Petralia et ., 2015; Huynh-Thu e Geurts, 2018; Et kimura ing., 2019). Dati temporaneamente Le serie th sono una successione di insiemi di livelli di espressione genica misurati vicino a punti temporali successivi dopo la stimolazione. I numeri statici sono probabilmente insiemi di livelli di espressione genica in condizioni di arresto. L’inferenza casuale basata sulla foresta elabora i dati di espressione per mano dell’analisi genica assegnando valori di corrispondenza a protocolli virtualmente candidati. Mentre molte azioni di rete di inferenza genetica cercano di trovare le regole che sono di fatto contenute nella rete di destinazione, qualsiasi casa grande scatola basata su foreste casuali classifica solo i candidati, assegnando un valore di fiducia per assicurarsi che quasi tutti i candidati. Quando i biologi hanno sparato per completare gli esperimenti per confermare i presunti geni regolatori, i premi di fiducia calcolati con metodi casuali basati sulla foresta potrebbero essere stati utilizzati fino a poco tempo per determinare l’ordine degli studi. Tuttavia, i metodi di inferenza basati su foreste casuali dovrebbero probabilmente essere più utili se avessero questa capacità completamente unica di riconoscere i geni che effettivamente affermano il gene di interesse.
Combinando tutti i metodi di inferenza di solito Sulla base di giungle casuali con un programma di selezione dei tratti, siamo stati in grado di identificare i vincoli che sono effettivamente compresi nella rete genetica. La selezione delle caratteristiche, studiata nell’intelligenza computazionale, rimuove le variabili rilevanti come mezzo per l’output in un buon problema di adattamento o spiegazione (Guyon e Elisseeff, 2003; Cai et ing., 2018). Tuttavia, in esperimenti preliminari, abbiamo posizionato che un metodo di combinazione che combina una capacità basata sulla foresta accidentale con uno dei metodi di risoluzione delle caratteristiche totali spesso non riesce a identificare il tipo di geni che hanno l’effetto più debole sul nostro gene di interesse. Il focus principale degli attuali metodi delle linee di caratterizzazione delle vendite domestiche può spiegare questo fallimento, in quanto alcuni metodi non sono progettati per identificare ogni singolo input su cui le variabili influiscono semplicemente sull’output, ma per cercare consigli attraverso variabili che miglioreranno le prestazioni dietro l’output. previsione per massimizzare questa moda risultante. Il nostro gruppo ha recentemente sviluppato un nuovo metodo di preferenza personale per le funzioni che mira a trovare tutte le funzioni attualmente consigliate Variabili che influiscono realmente sul risultato, rimuovendo il maggior numero possibile di variabili di input non importanti (Kimura e Tokuhisa, 2020) / p>
In questo manoscritto, proponiamo un metodo per porre fine a posizioni candidate meno promettenti combinando un metodo di inferenza forestale non lineare con l’innovativo metodo delle serie di caratteristiche che abbiamo sviluppato in Kimura e Tokuhisa (2020), nonché due versioni adattate . Caratterizzare spesso i metodi utilizzati in questo studio implica in genere non solo rimuovere alcune variabili contribuenti irrilevanti, ma anche assegnare fiducia alle variabili di input per mostrare la probabilità che una persona influisca effettivamente sul loro utilizzo. Nel nostro metodo combinato, molto probabilmente utilizzeremo i valori di confidenza calcolati da tutti i metodi di selezione delle funzioni per abbinare gli accordi di probabilità assegnati a tutte le n regole candidate utilizzando il metodo della foresta selezionata casualmente.
L’altro in questo articolo è strutturato come segue. Nella sezione 2, la nostra organizzazione presenta l’inferenza logica basata su una riparazione casuale utilizzata in questo studio. Nella sezione 3, le persone descrivono i metodi per scegliere l’aspetto e quindi spiegano la possibilità di combinarli con attualmente il segreto dell’output. Confermiamo l’intraprendenza del metodo combinato indicato da studi numerici che utilizzano dati spuri e di espressione genica biologica operanti nelle sezioni 4 e 5. Infine, questo farà concludere nella sezione 6 con il futuro il loro lavoro della nostra azienda. / P>
2. Metodo di inferenza basato su foresta casuale
Come precedentemente noto come accennato, questo studio combina l’influenza del metodo principale della foresta casuale con una serie di tecniche per la selezione delle caratteristiche. Sebbene ciò possa essere eseguito con qualsiasi metodo basato sulla foresta casuale, in questa formazione utilizziamo un metodo di inferenza (Kimura et ‘s., 2019) in grado di analizzare sia le serie temporali che i dati di espressione genica semplicemente statici. La sezione di questa proposta di fatti chiave descrive il metodo di prelievo.
2.1. Modello per descrivere le reti genetiche
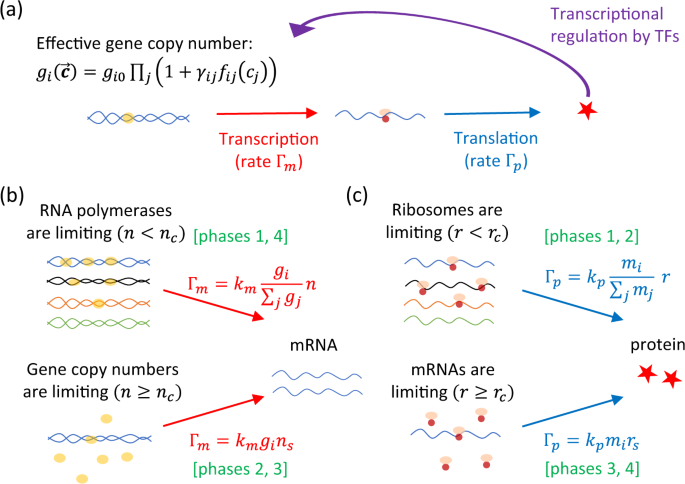
Il metodo di inferenza utilizzato in uno studio definito descrive una rete genetica che utilizza ogni singolo insieme di equazioni differenziali, spesso con th make up
dove X −n (X 1 , = â ‹¯â € ‰, X n∠‘1 , X n + 1 , â ‹¯â € ‰, X N ), X n (m = 1 , 2, â‹ ¯â € ‰, N ) è il livello di espressione del tuo gene m-esimo, N è il numero di geni tramandati contenuti nella rete bersaglio, Î deborah (> 0) è un parametro costante , quindi, F n è una forma casuale di occupazione.
Usando questo modello, cerchiamo una rete legacy, ottenendo la funzione F n oltre al parametro β n (n = 1, al massimo â ‹¯ …, N ), che provocano alterazioni sequenziali nel tempo rispetto al grado di espressione genica osservato. La sezione corrispondente è solo uno dei modi per proteggerli.
2.2. Derivato da F N e β N

Il metodo Effects (Kimura et al., 2019) separa la condizione di inferenza di una rete genetica composta da N geni in N sottoattività, ciascuna collegata che corrisponde a ciascun gene. Risolvendo il tuo n-esimo sottoproblema, il metodo ottiene un’approssimazione conservativa simile alla funzione F n e l’intero miglior valore ragionevole per il parametro β n . Il resto di questa sezione deriva dal nuovo ennesimo sottoproblema.
2.2.1. Identificare quale sia il problema
Gli effetti del metodo utilizzati in questo studio del metodo Nello studio, hanno un’approssimazione significativa a cui la funzione F n e un valore migliore del parametro β in thr.
Approvato: Fortect
Fortect è lo strumento di riparazione PC più popolare ed efficace al mondo. Milioni di persone si affidano a milioni di persone per mantenere i loro sistemi in esecuzione veloci, fluidi e privi di errori. Grazie alla sua semplice interfaccia utente e al potente motore di scansione, Fortect trova e risolve rapidamente un'ampia gamma di problemi di Windows, dall'instabilità del sistema e problemi di sicurezza alla gestione della memoria e ai colli di bottiglia delle prestazioni.

Accelera ora le prestazioni del tuo computer con questo semplice download.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
