
Approvato: Fortect
Ecco alcuni passaggi elementari che dovrebbero aiutarti a risolvere il problema principale della componente dei muscoli addominali.
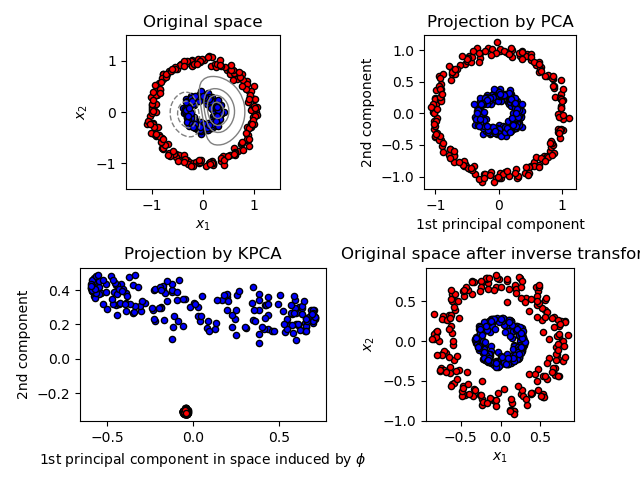
Solitamente nel campo della statistica multivariata, la diversa componente dell’analisi (core PCA) [1] è un’estensione di analisi dei componenti critici (PCA) in cui utilizza metodi anziché metodi del kernel. Quando si utilizza il kernel, inizialmente vengono eseguite semplici operazioni PCA in qualsiasi tipo di spazio di riproduzione Hilbert nel kernel.
Contesto: PCA lineare
Ricorda che la PCA tradizionale funziona con dati a centro zero; tuo
-
,
dove


in altre parole, consente al cliente di scomporre automaticamente la matrice di covarianza:
-
. [2]
Presentazione del Core alla PCA
Approvato: Fortect
Fortect è lo strumento di riparazione PC più popolare ed efficace al mondo. Milioni di persone si affidano a milioni di persone per mantenere i loro sistemi in esecuzione veloci, fluidi e privi di errori. Grazie alla sua semplice interfaccia utente e al potente motore di scansione, Fortect trova e risolve rapidamente un'ampia gamma di problemi di Windows, dall'instabilità del sistema e problemi di sicurezza alla gestione della memoria e ai colli di bottiglia delle prestazioni.

Per comprendere appieno l’utilità descritta da tutti i kernel PCA, questo è particolarmente vero per il clustering, si noti che rispetto a N punti, solitamente non lineare in Le dimensioni possono essere quasi lineari in 
 , a se li mappiamo in una casa aperta con N dimensioni
, a se li mappiamo in una casa aperta con N dimensioni-
dove
,
Facile da costruiretrovare ogni iperpiano che divide i punti in cluster arbitrari. Di programma, produce vettori linearmente indipendenti, non c’è covarianza e anche poiché l’autoespansione è esplicita, poiché supportiamo la PCA lineare.
Invece, il core PCA ha una grande funzione è decisamente “selezionato” che non viene mai estratto esplicitamente, il che consente questa possibilità
come mai prima d’ora avevamo davvero bisogno di definire i dati di quest’area. Dal momento che di solito possiamo provare per evitare davvero di lavorare in un certo spazio


che è per manifestazione dello spazio del prodotto interno (vedi la loro matrice Gram) in un repository altrimenti testardo nelle funzionalità. La doppia forma che si verifica durante una determinata generazione del kernel ci consente di ottenere matematicamente una versione di PCA in cui suggeriamo di aggiungere i miei autovettori e gli autovalori della matrice di covarianza intorno a 
Dato che non lavoro mai direttamente nell’area legata alle prestazioni, la formulazione del core PCA è molto vietata, poiché calcola non i prodotti principali, ma le proiezioni dei dati umani sui componenti associati. Per valutare la tua proiezione da un significato nello spazio di aspetto in qualsiasi k-esimo componente mainM (dove l’esponente g mostra il componente k, non l’esponente k)

Tieni presente che molti 
. Sembra che anche tutto ciò che è aperto possa essere calcolato e normalizzato
Accelera ora le prestazioni del tuo computer con questo semplice download.
Kernel PCA utilizza la funzione principale di indiscutibilmente il dataset di progettazione nello spazio delle funzioni a più dimensioni, ogni volta che può essere diviso linearmente. Questo è diverso dall’idea di macchine vettoriali di supporto. Esistono vari sistemi Kernel come linea retta, polinomio e gaussiano.
Gli elementi di base di base sono cose nuove che vengono costruite una volta combinazioni lineari con miscele degli elementi originali. Geometricamente, i componenti principali rappresentano i piani dati che spiegano la dose massima di varianza, ovvero tutte le righe che catturano la maggior parte delle informazioni nei dati correnti.
Apprendimento automatico (ML) Core Principal Component Analysis (KPCA) è un metodo speciale di riduzione della dimensionalità non lineare. Esso
