
Today’s article is meant to help you when you get an internal or firmware error.
Approved: Fortect
In modern systems with nor-flash (protected) BIOS that use booting from USB or SATA / IDE drives, SD card and CF card are probably the best choice for design, and these types of peripherals are usually driven by industrial NAND flash memory. Nor-Flash (proprietary) is part of the model that helps manage errors on NAND-Flash.
- SLC (single cell)
- MLC-Level (two-level cell – which can be used during pseudo-SLC)
- TLC (three-level cell)
- 3D – (XYZ Grid Matrix)
All of these technologies are excellent and have a long lifespan as stated in Flash Endurance. You may need interfaces, complex hardware, and firmware to work properly. The raw bit error rate in MLC / TLC is quite high and requires ECC algorithms for heavy duty error detection as well as correction. > 96 bits detection / correction is roughly our average for MLC / TLC.
How does NAND flash fail?
NAND flash memory is inherently problematic due to its quality (the number of cells depends on the charge). Here is a list of typical failure modes :
- Decrease or increase in cellular power
- Read errors
- Program errors
- Excessive program / uninstall cycles
Using a well-designed city NAND controller can build or break a memory product. The controller wants to have a properly designed Flash Translation Layer (FTL) in its hardware / firmware to avoid errors.

He is responsible for the linguistic translation of a logical task into a physical task. Logically Critical (LBA) for physical display in sectors (Blocks-> Pages-> Sectors). Mapping is a practical and relatively easy part. Most controllers continue to use block-based matching or page-based matching. Both have their own meanings and their drawbacks. With a simple internet search attempt, you can find the complete FTL chart data if you want to do more in-depth research on which topic. The biggest challenge in FTL is error handling. As you can imagine, this becomes more critical with very and small geometry.and the MLC / TLC tool process.
Block wear often occurs after P / E cycles. LOCAL tests can help determine wear. The first consideration is to avoid premature wear of flash blocks that have a new life of only 3000 P / E rounds in small MLC / TLC devices. Wear leveling ensures that all blocks have the same number of P / E cycles. The best wear leveling is in sleep mode, where blocks of data are transferred even virtually as written (static data moves frequently).
Good FTL maintains delete qualification for each block, is active, and triggers a reliable wear level as soon as a predetermined number of deletions are reached. Thus, wear compensation is really the first important step in troubleshooting.
This function is usually performed in hardware. Errors are generated when reading data from flash memory, there is no way out. The best designs use a combination of ECC and CRC to avoid misdirecting and correcting data. UseThere are different algorithms, but the most efficient is the BCH algorithm. This requires 13 bits for the desired overload correction bit.
Data for improved aerial detection is stored in the flash reserve area, so the degree of correction applied depends on the flash offered in the antenna coverage area. Flash vendors are configured in such a way that the ideal FTL keeps track of how thousands of bits need to be corrected on each read, sometimes as data changes. There are good reasons for this, as we will see.
This phenomenon is often overlooked by many controller manufacturers and should not be. Read fault bugs for remedies for many cryptic problems in the field.
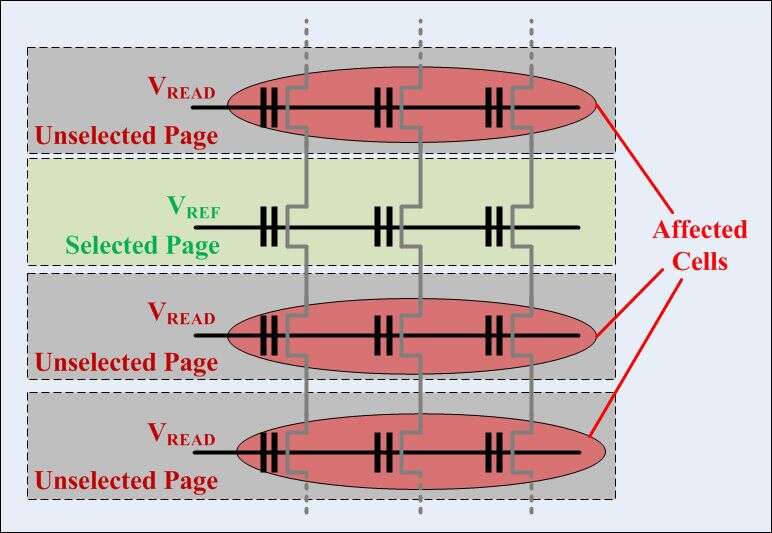
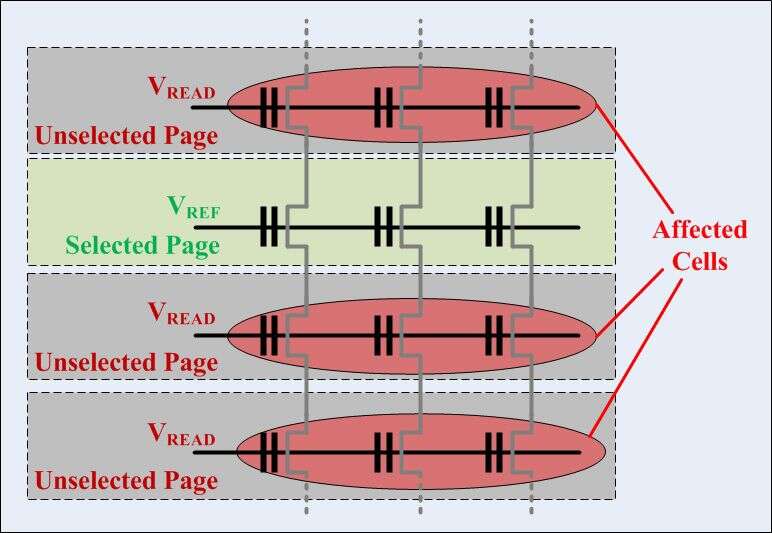
Read interference errors occur when there are too many (approximately 1 million) pages on a page without the need to remove the intermediate block. Stabilizing static wear helps to some extent, but it may not be enough. Wear levels Basic safety mechanism to prevent too many erase cyclesprograms in the block. What is needed is to count one of the number associated with block / page reads. At the end of its useful life, the data must be moved to the newly deleted unit, as the deleted unit can be put back into service.
The problem with reading is that they affect not only the specific page you are reading, but also adjacent pages. This is dangerous because mistakes that occur when reading the affected passage may not be correctable.
Why does NAND flash wear out?
Programming errors usually occur when too many incomplete pages are actually programmed and adjacent pages are violated. One way to avoid this is to limit the number of partial page programs. There is no set limit on the use of read noise, and other mechanisms can be used to minimize this. This happens when reading the affected page and detecting an actual error. Sometimes this can usually be fixed, but if any problem occurs, the block is still retained.
So what should we do? Opera One thing that can help is keeping track of the number of bits that need to be corrected for each page read. When a small amount of available corrective capacity approaches, the block should be removed after the data file has been moved to another good block, and then the route can be used again.
Misunderstandings in NAND flash are much less common than erase errors. When learning fails, it is not always necessary to take the unit out of service. Suspending a lock would be ineffective and unnecessary. Just select “Limit”, copy the data from the old unwanted block to the new one and delete the block that caused the error. He is then ready to return when you need service.
If the delete fails, the result will be more severe. Eliminate errors when a block is removed but also replaced (reassigned).
Flash devices are shipped from the factory with bad block markings. Usually all good partitions contain 0xFF. The manufacturer detects bad blocks on the minimum first pages of the detail block, differentnym from 0xFF. The first group order for each controller is to scan them and create a fault table. These blocks are not included in the physical assignment. Manufacturers usually state that bad initial + temporary shoes do not exceed a percentage of the total number of blocks. Usually 2% is given. It is important that the spare block pool is tested directly to replace these blocks as they are pretty bad, so a bad reallocation block should be mandatory.
What is internal flash memory?
NAND flash has a function of internal copying of data from one block to another. This can help the augmentation run about 20% faster. Data never crashes the flash memory of your device. However, the big drawback is the lack of bug fixes. Do enough this time and bit errors will be accounted for. So what can you do to prevent this from happening? Limit the number of incineration processes performed with a counter. If the threshold is usually exceeded, read the detailed controller entries to correct most errors. Then reset the counter. It turns out that this is x A great compromise in terms of cabin reliability and speed.
We can now see that errors occur in different ways when using NAND flash, and why handling NAND flash slippage is so important. All of the above paths should be used to minimize the occurrence of errors.
However, obstacles will still arise. Take trouble reading flash memory. Above, we have already mentioned a method that allows you to accurately track the number of carefully corrected bits on each read. By observing this counter, we can tell if the block is getting worse. When 75% of its corrective power is reached, block removal helps.
Approved: Fortect
Fortect is the world's most popular and effective PC repair tool. It is trusted by millions of people to keep their systems running fast, smooth, and error-free. With its simple user interface and powerful scanning engine, Fortect quickly finds and fixes a broad range of Windows problems - from system instability and security issues to memory management and performance bottlenecks.

Although we’re talking about the controller reading the page and still getting an unrecoverable error. He does not understand if the error is complex or not, possibly due to a reading disorder or use of tools in the past. Therefore, the controller must read for several days in a row to see if the penalty has been reached. In this case, it is recommended to schedule a block update so that the program is removed and the data moved to another blok. If the deletion fails, it just needs to be reassigned.
If this cannot be fixed, an error message with no data is sent to the host. This is a bad scenario and can be minimized with the methods described above. From the tier, all media that affects critical data must be stored in multiple locations on disk.
In the case of typographical errors related to Flash errors, the controlled entity should move existing data to the current new block, program new pages and website pages, and schedule an update to the block. I AM.
Speed up your computer's performance now with this simple download.![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
