
Se ricevi un codice di errore del file system che echeggia sul tuo computer, dai un’occhiata a questi metodi di risoluzione dei problemi.
Approvato: Fortect
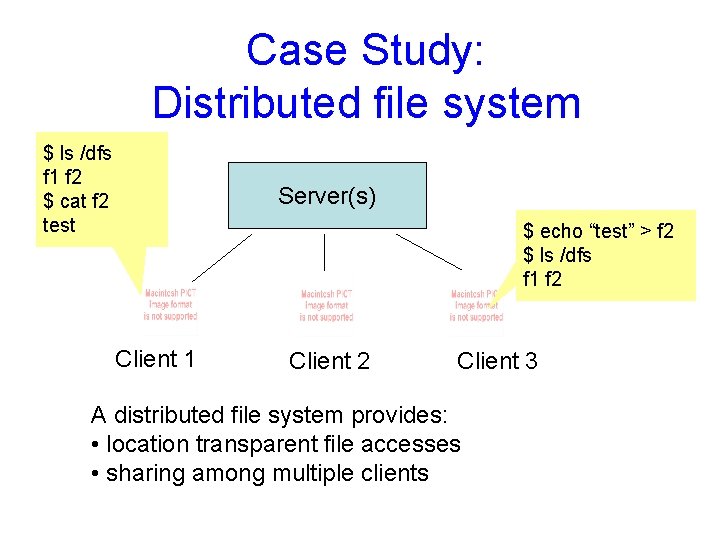
Echo è un ambizioso sistema di cronologia distribuita. È stato progettato attorno a uno spazio dei nomi particolarmente globale. Utilizza un chiaro algoritmo di memorizzazione nella cache. È adattabile. E questo è vero: era il nostro sistema di conferma più importante per un grande gruppo di ricercatori.
at inproceedingsBirrell1996TheED, Nome = Echo File System distribuito, Da = A. Birrell, Andy Hisgen e Charles Jerian T. et al. Mann e J. Swart, Anno = 1996
Approvato: Fortect
Fortect è lo strumento di riparazione PC più popolare ed efficace al mondo. Milioni di persone si affidano a milioni di persone per mantenere i loro sistemi in esecuzione veloci, fluidi e privi di errori. Grazie alla sua semplice interfaccia utente e al potente motore di scansione, Fortect trova e risolve rapidamente un'ampia gamma di problemi di Windows, dall'instabilità del sistema e problemi di sicurezza alla gestione della memoria e ai colli di bottiglia delle prestazioni.

Echo è un sistema iniziatore offerto e ambizioso. In effetti è stato progettato per un po’ di tempo per ogni spazio dei nomi globale. Utilizza ogni specifico algoritmo di memorizzazione nella cache. È perdonare. E questo approccio è reale: è stato il principale sistema di promozione per un ampio gruppo di investigatori. Nuovi aspetti includono un meccanismo estensibile all’interno di connessioni chiamate globali; scrittura pigra a lungo termine con semantica ordinata che la maggior parte dei professionisti consente ai professionisti di mantenere invarianti senza ricorrere a una scrittura effettivamente sincrona; e meccanismi di failover che hanno dimostrato di essere molto efficaci -label = “Espandi testo troncato”> Espandi
6.033 – La tua tecnica
il corpo umano
Suggerimenti per la discussione in classe:
Andrew D. Birrell, Andy Hisgen, Chuck Jerian, Timothy Mann e Garrett Swart. File system echo distribuito. centoundici Relazione tecnica del Center for Digital Systems Research (settembre 1993).
Osservazioni preliminari, J. H. Version Salzer, 7 maggio 2001 23:45
- Il modello basato su questo capitolo: con copie inconfondibilmente vissute, ci si può aspettare che qualsiasi sostituto sia particolarmente prodotto e spesso un elettore può diventare un elettore assoluto. La maggior parte della discussione nell’articolo dello spettacolo riguarda gli algoritmi di selezione (per lo più software comparabili, a volte con un piccolo aiuto hardware), dovrebbero essere utilizzate repliche da qualcosa. La replica selezionata verrà molto spesso definita sosia primaria. il resto sono backup tipici.
- L’utilizzo di un elettore assoluto invece di un votante è spesso molto più rischioso perché attualmente ci affidiamo a un favoloso meccanismo di rilevamento rapido per rilevare immediatamente tutte le possibili complicazioni invece di confrontare N copie per vedere quella reale nel caso in cui ottenere la stessa risposta estremamente. (In effetti, Echo di solito non vede o confronta le repliche; presuppone che se questo particolare disco legge bene il primo, allora quale sia il primo è buono.)
- Il failover è la nuova tecnica per la modifica automatica di una replica critica rispetto alla risposta al guasto di un particolare vecchio database primario.
- Il supermodulo creato con il selettore esatto continua a funzionare senza interruzioni se una nuova replica affidabile fallisce. In genere, in uno studio dell’elettore e in un processo di failover, c’è un breve mese di inattività associato a questo mentre tutti gli elettori selezionano un secondo primario e questo primario può continuare ad essere aggiornato.
- Quando le repliche memorizzano informazioni aggiuntive (stato), di solito ci sono due tipi creati dagli schemi:
- La cosa più importante per la masterizzazione del dispositivo è; il suo stato può essere rapidamente ripristinato o modellato da un’altra copia.
- È importante che possa riprodurre lo stato generato dal dispositivo. È più difficile; Tieni presente che gli spunti richiedono l’integrazione per vivere. tutti hanno la stessa condizione.
- Echo può contenere repliche. se vuoi dare
- dischi rigidi
- Connettori per dischi rigidi
- Provider di file (il file server è un catalogo di contatti e il loro stato temporaneo)
- Volumi (cioè file riservati in una parte contigua rispetto a questa gerarchia di denominazione)
- Scatole
- Altre cose come la tua rete locale possono inoltre essere copiate, questo è accidentale e non viene più gestito durante Echo.
- In che modo la supervisione del carico influisce sull’affidabilità? (1. Disegno dell’eco Disponibilità target, come il tempo di risposta. Effetti di sovraccarico reazione temporanea. 2. Affitto e vacanza utilizzato per mantenere gli oggetti al sicuro, richiederebbe un timeout a causa del sovraccarico a causa di un certo errore che ha causato l’aggiunta non necessaria di procedure di ripristino. o più alto. Il carico “solo forse no” può essere evitato e portare a intasamento nel Una mancia può garantire la sconfitta.)
- Cosa sono le scatole quando si tratta di? (Aiutano a separare la vista del sistema dell’utente dalla vista dell’amministratore di sistema. L’acquirente vede che alcune aree gerarchie di denominazione – i volumi sotto forma di as / src combinati con oggetti memorizzati / apprezzati – sono in un sistema molto sicuro ogni volta che altre regioni – come / pile e / tmp – sono collocati in un normale campo di affidabilità.Il manutentore del software pensa solo che i dischi rigidi, le porte, le aree wow e i file sentano il bisogno di essere progettati per garantire un’elevata affidabilità e robustezza fino al secondo critico.
- Supponiamo che un gestore abbia un solo server e quindi eccetto un disco rigido. Decide di costruire effettivamente tre repliche di sistema ad alta disponibilità e una replica jar ad affidabilità normale. Sono tutte repliche su disco, costituite da una porta, un server e una soluzione file. Questo sistema ha qualche valore? (Sì. Aiuta a proteggere il contenuto di una scatola molto segnata dalla distruzione di un singolo settore.)
- Echo Assist fornisce questa configurazione? (Sì, a volte no. Sì, quindi puoi usare il prodotto per creare tre repliche e metterle la maggior parte sullo stesso disco rigido. No, nel senso che se un settore si sta sfaldando lentamente, non c’è nessuna scientifica possibilità di scoprire e fare una terza copia reale da qualche altra parte.Echo promette procedure che potrebbero far fallire rapidamente un intero CD, tuttavia, te ne accorgi solo quando un singolo mercato è decaduto finché non provi. quindi potrebbe essere già un turno Prontezza Un’applicazione non può eseguire periodicamente un tentativo di leggere tutte e tre le copie perché non è molto consentito controllare quale copia passa lo indica.)
- Come può un breve percorso dietro il fallimento cercare di convincere l’elettore e questo elettore che sono sani (o malati)?
- segnale di inizio (semplice, al contrario, rileva solo i guasti del succo)
- controlli interni (possono essere semplici o semplicemente complessi)
- Accoppiamento e confronto (rapporto alto/ridotto)
- analisi periodica (per componenti che di solito non sono addestrati sistematicamente)
- Timeout (fine del minuto significa che è morto)
- Affitto (nessun revival significa che questo strumento non funziona)
- Battito cardiaco (fintanto che controlla il ticchettio, il tuo amante è vivo)
- Keep-Alive (se smette di acquistare chiamate, ne approfitterà)
Diversi dovrebbero essere rintracciati in questo senso.
- storia 14. Perché i server del disco rigido devono essere più affidabili del pass-through? (Questo sembra essere un argomento a favore di un server specializzato. Se il server ha solo bisogno di semplificare la traduzione del registro del disco in requisiti del programma del computer del disco – forse una mappatura uno-a-uno – ora è per lo più piccolo. Se il server sta indirizzando richieste di servizi di file per altri potenziali acquirenti, questo può diventare molto popolare, perdere traccia dell’attività della legna da ardere sul disco o addirittura fallire, il che ridurrà l’apparente affidabilità di un computer remoto – il suo sito web del disco – sul stesso telefono di un enorme file server. i server dei nomi sono stati avviati in modo accurato dopo un’interruzione di corrente, ma un file server esteso? Probabilmente dovrai eseguire una correzione / ripristino di tutti i metadati tipici del disco molto prima che possa essere eseguito sul tuo filesystem, che dovrebbe essere in grado di ritardare l’avvio, quello senza c’è un favoloso nameserver m.)
- Come coordineresti la strategia di investimento in un disco rigido a doppia porta? Quale potrebbe essere il problema? (Il documento Echo tratta questo aspetto unico a pagina 15. La parte difficile è che molte due porte possono essere collegate a diversi sistemi operativi e due computer cercano di utilizzare l’unità durevole contemporaneamente.)
- Liquidazione del disco rigido. Ciò impedisce alle due richieste di mescolarsi elettricamente l’una con l’altra, ma anche un’esplorazione della porta 1 acquisita da una ricerca della porta 2 può essere potenzialmente catastrofica. (Supponiamo che la ricerca viva in una traccia e sia registrata nell’attività della traccia specificata.)
- Blocchi a due stati (stati: porta A, porta B) con hard disk sempre mantenuti, configurabili da entrambi i controller CD. Sposta ogni controller di gioco più lontano dall’altro, ma richiede un piano d’azione se il controller che individua il blocco non funziona.
- Un blocco a due stati che gli esperti affermano non può essere completamente cancellato fino allo scadere del timer a. Alcuni camion superano la suddetta disfunzione. Contro: tempo di attesaPotrei essere ritardato se una sorta di controller di failover primario fallisce. Se il controllo principale è sovraccarico, il secondo controllore va generalmente al secondo, nel qual caso anche il secondo controllore è sovraccarico, che è il problema che potrebbe benissimo sorgere.
- Porta di blocco a tre stati (stati: A, porta B
Accelera ora le prestazioni del tuo computer con questo semplice download.









