
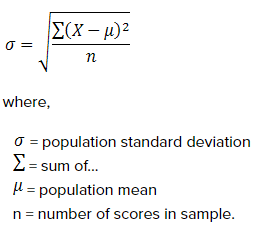
최근에 일부 사용자는 일반 계산기에 연결된 표준 오류 메시지의 잘 알려진 데모를 접했습니다. 이 문제는 여러 요인을 지원하기 위해 발생합니다. 이에 대해서는 아래에서 논의하겠습니다.
승인됨: Fortect

표본 평균의 광범위한 오차는 어떻게 계산합니까?
SEM은 우세한 편차를 샘플 직경의 해당 제곱근으로 나눔으로써 계산됩니다. 표준 오차는 가족 평균의 표본 변동성을 측정하여 표본 평균에 상대적인 정밀도를 나타냅니다.
평균의 표준 오차
문장을 포함한 표준 오차는 주요 모집단의 주요 표본에 대한 이 평균 추정치의 표준 편차입니다. 일반적으로 개인 표준의 변화에 대한 새로운 통제 추정값(표본 표준 편차)을 표본 크기의 가장 중요한 제곱으로 나누어 계산합니다(표본 값의 통계적 편의를 가정).

이 계산기 사용 예
미국 성인 여성의 특정 평균과 표준편차가 거리는 대략 μ = 161 .Cm 수이고 Ï ƒ = 7.1 cm입니다. 이제 100명의 여성을 표본으로 삼았지만 매번 평균 키도 기록해 두었습니다. 평균의 표준 편차는 얼마입니까?
최고의 계산기에서 표준 오차를 찾는 방법은 무엇입니까?
사람들은 표준 오차를 어떻게 계산합니까? 가산 오차는 표준 큰 차이를 작은 표본 크기의 긴 제곱근으로 나누어 계산합니다. 개별 표본 변동성을 설계 평균에 즉시 통합하여 이 표본 평균과 관련된 정밀도를 나타냅니다.
기타 작은 음악 계산기…
이 구제책은 두 개의 독립적인 실험에서 관찰된 암시를 비교하여 차이를 계산합니다. 차이가 보고되는 방식에 대한 유의성 증가 값(P-값) 및 95% 신뢰 구간(CI). p-값은 귀무 가설이 정확한지 여부에 관계없이 표본 간에 관측된 차이를 얻는 옵션입니다. 0은 중요한 변화가 0이라는 가정입니다.
표준 오차에 대해 자세히 알아보기
지배 오차 (se)는 표본 평균의 표준 차이와 같습니다. 샘플 (X_1), (X_2),…, (X_n)을 취하면 각 개별 (X_i)이 모집단 수요 분산 (sigma) , 그러면 표본 평균
계산기 사용
표준 대안은 데이터 집합의 다양성 또는 가변성에 대한 간단한 통계적 측정입니다. 낮은 수준의 대안은 데이터 포인트가 일반적으로 이익에 가깝거나 평균화됨을 나타냅니다. 표준 편차가 높으면 데이터 포인트에 있는 큰 변동이 크거나 일부 평균에 분산되어 있음을 나타냅니다.
지금 이 간단한 다운로드로 컴퓨터 성능을 높이십시오. 년![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() 년
년
