
Als je per bestandssysteem een foutcode krijgt op je gepersonaliseerde computer, bekijk dan deze methoden voor probleemoplossing.
Goedgekeurd: Fortect
Echo is een ambitieus gedistribueerd geschiedenissysteem. Het is gebouwd rond een bijzonder wereldwijde naamruimte. Het maakt gebruik van een enkel duidelijk caching-algoritme. Het is vergevingsgezind. En onderscheiden is waar – het was het meest interessante bevestigingssysteem voor een grote groep onderzoekers.
@ inproceedingsBirrell1996TheED, Naam betekent Echo Distributed File System, Door = A. Birrell, Andy Hisgen en Charles Jerian T. d'autant plus al. Mann en J. Swart, Jaar is gelijk aan 1996
Goedgekeurd: Fortect
Fortect is 's werelds meest populaire en effectieve pc-reparatietool. Miljoenen mensen vertrouwen erop dat hun systemen snel, soepel en foutloos blijven werken. Met zijn eenvoudige gebruikersinterface en krachtige scanengine kan Fortect snel een breed scala aan Windows-problemen vinden en oplossen - van systeeminstabiliteit en beveiligingsproblemen tot geheugenbeheer en prestatieproblemen.

Echo is een gedistribueerd en toegewijd initiatorsysteem. Het is inderdaad ontworpen wanneer elke globale naamruimte. Het gebruikt een bepaald type caching-algoritme. Het is vergevingsgezind. En dit klopt – het was het primaire activeringssysteem omdat een grote groep onderzoekers. Nieuwe aspecten integreren een uitbreidbaar mechanisme binnen verbindingen die globaal worden genoemd; langdurig lui schrijven met ordeningssemantiek die medisch gerelateerde praktijken in staat stelt om invarianten te behouden zonder toevlucht te nemen tot synchroon schrijven; bovendien zouden failover-mechanismen die u hebben bewezen zeer effectief moeten zijn -label = “Expand Truncated Text”> Expand
6.033 – Jij Techniek
het menselijk lichaam
Suggesties voor klassendialoog:
Andrew D. Birrell, Andy Hisgen, Chuck Jerian, Timothy Mann en Garrett Swart. Gedistribueerd echo-bestandssysteem. 111 Technisch rapport van het Centre for Digital Systems Research (september 1993).
Voorafgaande opmerkingen, J.H. Version Salzer, 7 mei 2001 23:45 uur
- Het model dat voornamelijk op dit hoofdstuk is gebaseerd: Met onmiskenbaar betrouwbare kopieën kan worden verwacht dat er vrijwel vervanging wordt geproduceerd, in combinatie met vaak kan een kiezer kiezer worden. Het grootste deel van de discussie in het echo-artikel gaat gewoonlijk over selectie-algoritmen (meestal softwaregerelateerd, soms met een beetje hardwarehulp), replica’s van iets zouden worden gebruikt. De geselecteerde replica wordt vaak de primaire replica genoemd. het gemak zijn typische back-ups.
- Het gebruik van een kiezer omvatten zaken als een kiezer is vaak veel serieuzer omdat we momenteel vertrouwen op een snel ontdekkingsmechanisme voor het onmiddellijk detecteren van alle mogelijke fouten in plaats van N-kopieën te vergelijken om de echte te zien voor het geval ze krijgen hetzelfde antwoord. (Echo leest of bekijkt in feite geen replica’s; het gaat ervan uit dat als de schijf de eerste goed vermeldt, de eerste goed is.)
- Failover is een techniek die betrekking heeft op het automatisch wijzigen van een kritieke replica als reactie die het falen van een bepaalde huidige originele database zal helpen.
- De supermodule die met de selector is gemaakt, gaat zonder onderbreking verder als een nieuwe reproductie mislukt. Meestal is er bij het leren van een kiezer in combinatie met een failoverproces een korte periode van uitvaltijd, terwijl de kiezer die tweede primaire selecteert en deze primaire zich bijgewerkt blijft voelen.
- Wanneer replica’s informatie (status) opslaan, zijn er meestal twee soorten schema’s:
- Het grote aantal belangrijke dingen voor apparaatreplicatie is; zijn vorm kan snel worden hersteld of gereproduceerd vanaf een extra kopie.
- Het is belangrijk om mijn status te reproduceren die door het apparaat is gegenereerd. Het is moeilijker; Houd er rekening mee dat cues moeilijk toe te voegen zijn om te leven. iedereen heeft dezelfde aandoening.
- Echo kan replica’s bevatten. geven
- echt moeilijke schijven
- Harde-schijfconnectoren
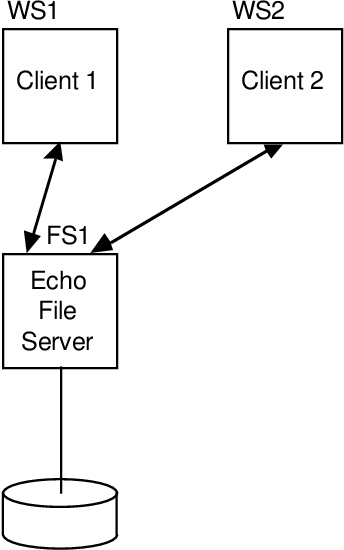
- Bestandsprovider (bestandsserver is een verzameling internetverbindingen en hun tijdelijke status)
- Volumes (d.w.z. nummers die zijn gereserveerd in een aangrenzend deel van deze identificerende hiërarchie)
- Dozen
- Andere dingen die vergelijkbaar zijn met je eigen lokale netwerk kunnen ook worden geript, dit is per ongeluk en wordt niet afgehandeld voor de duur van Echo.
- Hoe beïnvloedt de controle van de lading grote tevredenheid? (1. Echo-ontwerp Doelbeschikbaarheid, inclusief responsexemplaar. Overbelastingseffecten tijdelijke reactie. 2. Huur en dus vakantie gebruikt om items veilig te houden, kan een time-out vragen vanwege overbelasting door een fout die onnodige toevoeging van herstelprocedures stimuleert. 3. De “misschien niet” belasting kan worden gecontroleerd en kan vroegtijdig leiden tot verstopping in de Een truc kan een nederlaag garanderen.)
- Waar zijn dozen voor? (Ze vergemakkelijken de afzonderlijke weergave van het systeem door de gebruiker vanwege de weergave van de systeembeheerder. De gebruiker ziet waar bepaalde hiërarchieën met naamgeving van gebieden – volumes zoals en src gecombineerd met opgeslagen / gewaardeerde onderwerpen – zich in een zeer veilige doos bevinden wanneer regio’s worden toegevoegd – zoals / bin en tmp – worden in het normale stabiliteitsveld geplaatst.De software-onderhouder denkt dat harde harde schijven, poorten, wow-gebieden en bestanden moeten worden ontwikkeld om een hoge betrouwbaarheid en robuustheid te garanderen om u op de kritieke seconde te helpen.
- Stel dat de beheerder maar één server heeft en dus maar één niet-gemakkelijke schijf. Hij besluit om een paar systeemreplica’s met hoge beschikbaarheid en een containerreplica met normale betrouwbaarheid te maken. Het zijn allemaal replica’s op schijf, met een transport, een server en een bestandssysteem. Heeft dit vaardigheidssysteem enige waarde? (Ja. Helpt de inhoud van een zeer veilige doos te beschermen bij de vernietiging van een enkele sector.)
- Biedt Echo Assist deze configuratie? (Ja, ook laag. Ja, dus je kunt het gebruiken om drie replica’s op te leveren en ze allemaal op dezelfde harde schijf te plaatsen. Nee, in de zin dat veel als een sector langzaam uit elkaar valt, op dit moment geen isEr is geen wetenschappelijke manier om uit te zoeken en een derde absolute kopie te maken met een ander plan.Echo belooft procedures die ervoor kunnen zorgen dat een enkele hele cd snel faalt, maar je merkt het alleen op wanneer een individuele sector is gecorrodeerd totdat je het probeert.lees direct, en tegen die tijd is het misschien al een dag Gereedheid Een toepassing kan niet periodiek een test uitvoeren om alle drie de kopieën te begrijpen, omdat het niet mogelijk is om te controleren welke kopie er doorheen gaat.)
- Hoe kan een korte cursus van falen ernaar streven de kiezer en de kiezer te overtuigen wanneer ze gezond (of ziek) zijn?
- startindicator (eenvoudig, integendeel, detecteert alleen stroomstoringen)
- binnenkant van bedieningselementen (kan eenvoudig of complex zijn)
- Koppelen en vergelijken (hoge / lage verhouding)
- routinematige analyse (voor componenten die niet grondig zijn getraind)
- Time-out (einde van de timer betekent dat de applicatie dood is)
- Huur (geen verlenging betekent dat tool niet werkt)
- Hartslag (zo goed als hij het tikken onder controle heeft, hij leeft waarschijnlijk)
- Keep-Alive (als hij geen oproepen meer ontvangt, zal de persoon hiervan profiteren)
Verschillende kunnen in dit opzicht worden opgespoord.
- pagina 14. Waarom moeten harde-schijfservers veel betrouwbaarder zijn dan pass-through? (Dit lijkt een uitstekend argument te zijn ten gunste van een dedicated server. Als de server u alleen moet helpen om de schijfaanmelding bij schijfsoftwaredoelen te ervaren – misschien een één-op-één-toewijzing – dan is deze normaal gesproken klein. Als de server product- en serviceverzoeken voor andere potentiële kopers kan indienen, omdat het erg populair is, de logactiviteit tijdens de schijf uit het oog verliest of zelfs faalt, wat een bepaalde schijnbare betrouwbaarheid van een server – zijn hdd-website – op hetzelfde apparaat als een echte enorme bestandsserver. nameservers zijn gestart direct na een belangrijke stroomstoring, maar een enorme bestandsserver? U zult waarschijnlijk een herstel / herstel van alle typische schijfmetadata moeten doen voordat het op uw bestandssysteem kan worden uitgevoerd, wat zal vertragen beginnend, degene zondergo er is een nameserver m.)
- Hoe zou u investeringen in een bepaalde harde schijf met twee poorten coördineren? Wat zou een probleem kunnen zijn? (Het Echo-document behandelt dit op facebookpagina 15. Het lastige is dat twee steden op verschillende computers kunnen worden aangesloten en dat 3 computers hier tegelijkertijd de harde schijf proberen te gebruiken.)
- Arbitrage op de harde schijf. Dit voorkomt de twee verzoeken om elektrisch met elkaar te communiceren, maar een poort 1 lookup die allemaal wordt vastgelegd door een poort 2 lookup kan ook vaak catastrofaal zijn. (Stel dat de zoekopdracht zich in een waarneming bevindt en is vastgelegd in de sector van het gespecificeerde hoofdspoor.)
- Twee-standen vergrendeling (toestanden: poort A, poort B) met harddisk hold, configureerbaar op afstand van beide CD-controllers. Verplaatst elke controller verder van de andere, maar vereist een plan met actie als de controller die de obstructie detecteert faalt.
- Een vergrendeling met twee standen die niet volledig kan worden gewist totdat de timer is verstreken. Sommige vrachtwagens overwinnen het bovenstaande probleem. Nadelen: klaartijdIk kan vertraging oplopen als de grote failover-controller uitvalt. Als de hoofdcontroller is ingesneeuwd, gaat de tweede controller naar de tweede, in dit geval is de tweede controller overbelast, begrijpend dat dit het probleem is dat kan ontstaan.
- Blokkeringspoort met drie statussen (staten: A, poort B
Versnel de prestaties van uw computer nu met deze eenvoudige download.









