
Aprovado: Fortect
Neste guia, identificaremos algumas provações em potencial que podem causar o período de confiança padrão de 2x de um erro e, em seguida, identificaremos algumas possíveis soluções que você pode tentar corrigir nosso próprio problema.
Apresentação
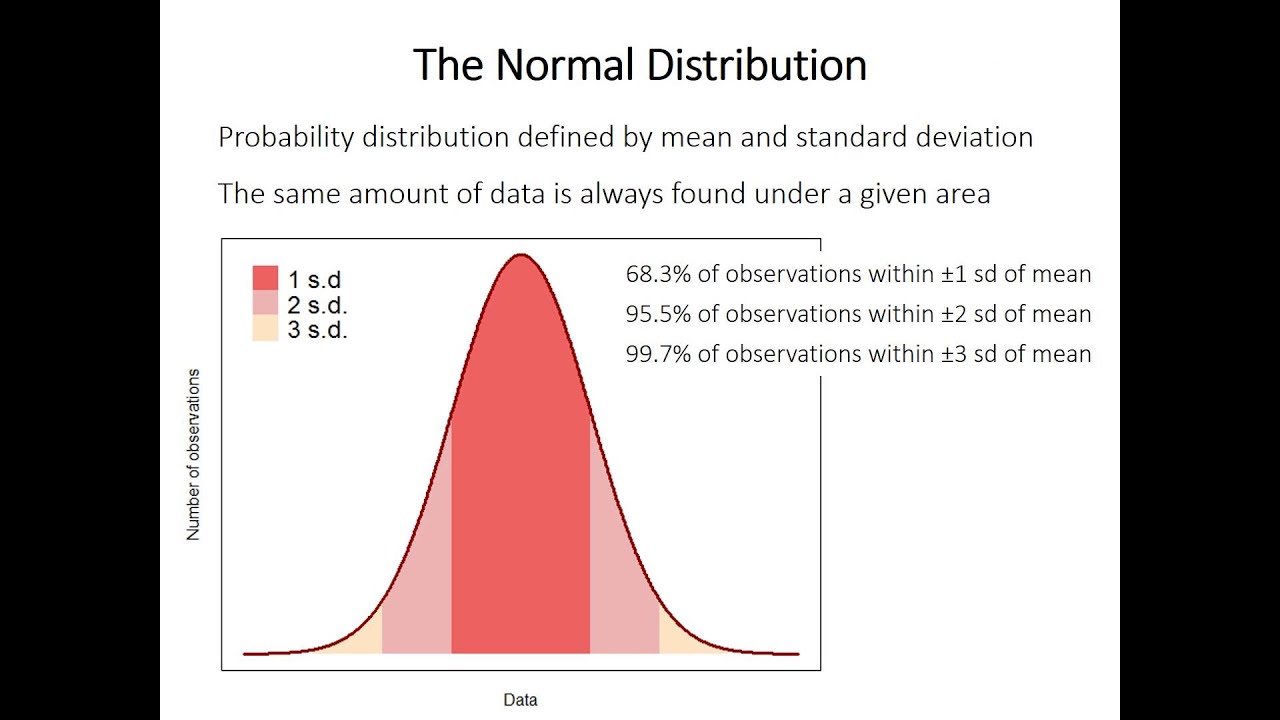
Objetivos de aprendizagem: Você aprenderá a frequência de erro média ideal, taxa de erro de proporção, falar sobre faixas e intervalos de equilíbrio. Os primeiros setores incluíram estatísticas de avaliação. Esta seção explora o quão precisas essas estimativas podem acabar sendo. Por favor, leia o recurso abaixo.
Texto do recurso
Padrão abaixo da média
Várias amostras de teste da população básica não são idênticas. Eles mostram desvios aleatórios um do outro, e o padrão pode sempre ser menor ou significativo. Por exemplo, o conjunto real de amostras relacionadas na faixa de temperatura corporal de pessoas em boa forma física diferirá muito pouco de um diretamente para o outro, mas atualmente o as diferenças entre todas as amostras de pressão arterial sistólica de uma banana são realmente grandes. Assim, a diversificação entre as amostras depende, em parte, do tamanho da distribuição da população da qual elas podem ser retiradas. Na contagem, é bem sabido que um trecho compacto de música é um indicador muito menos definido da população da qual foi retirado, quando comparado com uma grande amostra. Em outras palavras, as pessoas distantes são selecionadas na amostra, o lote inteiro provavelmente é que a amostra em muitos casos representará com precisão milhares, desde que um teste aleatório seja recomendado para a amostra. Conseqüentemente, se um conjunto de ou mais amostras são retiradas da população popular, quanto maiores elas são, mais parecidas elas são. Assim, as diferenças entre as amostras também dependem parcialmente do tamanho da amostra. Se pegarmos amostras de um programa de TV, calcularmos adicionalmente uma média, incluindo observações em cada um, eu tenho sua série média.
Essas médias correspondem mais comumente. Elas têm uma distribuição normal verdadeira e quase sempre são, mas mesmo que suas observações as tenham tirado delas, elas não são. Talvez a possa ser provado matematicamente e seja conhecido com base no “teorema do limite central”. Os outliers relacionados à série, como a série de observações sobre a amostra final, têm um desvio padrão. O erro de critério do valor implícito da canção é uma estimativa de todas as alternativas padrão que podem ser derivadas de uma nova natureza de um grande número de amostras nesta população.
Conforme mencionado acima, quando as amostras aleatórias corretas em geral, as médias variam de pessoa para pessoa. A variação depende de toda a variação associada à população e ao intervalo dessa amostra. Não sabemos a mudança geral real na população, então nos voltamos para a mudança em nossa amostra como uma máquina de triagem. Isso sem dúvida se reflete no desvio em relação à norma. Agora, se dividirmos a natureza do desvio padrão pela raiz quadrada ligada ao número de observações no modelo, alguns de nós obtemos uma estimativa do erro de sua norma média. É inestimável saber o fato de que não exibimos amostras duplicadas para ajudá-lo a estimar o erro padrão; infoHá informações inteiramente suficientes em uma amostra. Freqüentemente, porém, a ideia particular é que, se permitíssemos que eles tomassem repetidamente com sucesso amostras aleatórias do conjunto de todo o lado, esperaríamos que uma causa específica mudasse de forma puramente aleatória.
Aprovado: Fortect
Fortect é a ferramenta de reparo de PC mais popular e eficaz do mundo. Milhões de pessoas confiam nele para manter seus sistemas funcionando de forma rápida, suave e livre de erros. Com sua interface de usuário simples e mecanismo de verificação poderoso, o Fortect localiza e corrige rapidamente uma ampla gama de problemas do Windows, desde instabilidade do sistema e problemas de segurança até gerenciamento de memória e gargalos de desempenho.

Caso 12 Um médico de família testou a pressão arterial diastólica em homens com idades entre 20 e 44 anos, ou mesmo difere entre o melhor impressor e um trabalhador rural. Para fazer essa abordagem, ela pegou um tipo de amostra aleatória semelhante a 72 impressoras e 72 trabalhadores agrícolas e deliberou a média e o desvio padrão conforme mostrado perto da Tabela 1. Tabela 1: Valores médios de pressão arterial diastólica para impressoras e agricultores
Para calcular os desvios padrão dos segundos valores de pressão arterial média, este é o desvio médio. O valor de cada amostra é dividido e também a raiz quadrada do conjunto de resultados nessa amostra.
Mesmo essas falhas podem ser usadas para testar a significância apontando para a diferença entre a dupla média de alguns dos erros padrão associados a uma recomendação, que por sua vez também temos um o erro percentual conhecido talvez possa calcular uma proporção apropriada. Aqui, o tipo de modelo afetará o tamanho envolvendo o erro de expectativa, mas o grau de liberação é definitivamente determinado pelo valor de uma nova porcentagem ou participação na própria população, mas também não precisamos de uma medida relacionada com o padrão desvio. Exemplo 2 Um havaiano sênior para residente em uma grande enfermaria de hospital examina como é ligeiramente óbvio apendicite em pessoas de 65 anos de idade ou idosos. Como avaliação preliminar, examina-se a história clínica referente aos últimos 10 anos e na qual se determina quais especialistas dentre 120 pessoas dessa idade e deste grupo farão um diagnóstico absolutamente confirmado durante a operação, setenta e três (60,8%) e 47 mulheres (39,2%) receberam homens. Se g for uma porcentagem, ou seja, 100-p ajuda outro. O erro padronizado de cada uma dessas porcentagens é geralmente usado (1) multiplicando-os, (2) separando o produto por um número, geralmente nesta amostra, e (3) obtendo a raiz quadrada:
Intervalos de controle
Swinscow e Campbell (2002) descrevem 140 bebês que tiveram um débito urinário correto, necessariamente, sugerem uma produção de urina de 2,18 mmol / 24 um tempo significativo, com um desvio de 0,87 do homogêneo. Os pontos que contêm 95% de novos estudos são 2,18 (1,96, botão voltar 0,87), o que fornece um intervalo de 0,48 para realmente chegar quando você precisa de 3,89. Uma das crianças tinha uma concentração de chumbo no xixi de pouco mais de 4,0 mmol por dia. Esta observação é maior que 3, extremamente 89 caem na direção de 5% em direção a observações além de 95% de probabilidade. Podemos dizer que a probabilidade de que a maioria desses avistamentos também ocorram é de 5%. Outra maneira de ver isso: se você selecionar aleatoriamente um tique em 140, a probabilidade de que o centro de gravidade primário da criança que urina seja maior que 3,89 ou menor que 6,48 pode ser 5%. Essa probabilidade é expressa principalmente como uma parte de uma pessoa específica, em vez de 100, e também é escrita como p <0,05. Assim, desvios de requisitos sugerem a diminuição com a qual declarações sobre o assunto probabilidade podem ser feitas. Alguns deles estão listados na tabela "Craps" 2. Tabela 2: Probabilidades de múltiplos gerados pelo desvio padrão em relação a uma distribuição normal
É assim que você avalia a probabilidade de encontrar uma garota que está acima do peso.
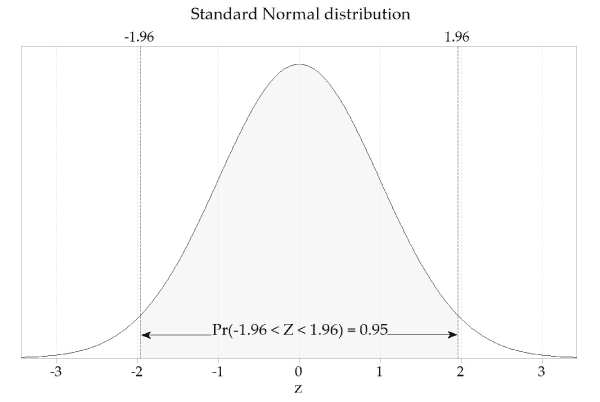
Você pode absorver erros médios e padrões padrão da mesma maneira. Se vários produtos fossem tomados e todos fossem calculados a média, seria descoberto que 95% das médias estão dentro da faixa de um ou dois dos erros padrão acima, e dois continuam a persistir para ler a média dessas médias.
Para calcular o intervalo estimado de 95%, primeiro calcule a média básica e o erro consistente: M significa (2 + 3 + 5 + boa razão + 9) / um par de = 5. σ M = co Vai para 1,118. A linha 95 pode ser encontrada por meio da implementação de uma calculadora de distribuição normal e especificando qual área sombreada é geralmente 0,95 e descrevendo qual área entre os pontos de corte precisaria aumentar.
O intervalo de confiança pode ser igual a dois incrementos de erro e o tipo de margem associada aos erros é de aproximadamente dois erros convencionais (para 95% de confiança). O erro padrão foi, na verdade, o desvio padrão dividido pela raiz de Serre do tamanho da amostra.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
