
Если вы получили сообщение об ошибке генетической сети, сегодняшнее руководство пользователя было создано для вас.
Одобрено: Fortect
Продолжить
Несколько исследований были посвящены влиянию техник случайного лесопользования на их превосходную производительность. Некоторые из этих методов эффектов также обладают надежной способностью анализировать временные ряды, а также определять ген слова. Однако они полезны только для соблюдения всех своих правил, связывая аспекты доверия. Ни один из них не смог обнаружить конкретные правила, которые на самом деле влияют на основной ген, чаще всего связанный с интересом. В этом конкретном исследовании мы предлагаем этот метод сокращения малообещающих правил-кандидатов, по существу объединяющий случайный вывод леса с помощью ряда методов выбора признаков. В качестве подходящего компонента для обнаружения неверных правил наша платформа, использующая результаты процедур выбора функций для согласования значений достоверности почти подразумеваемых нормативных требований, фактически была рассчитана с использованием методов, основанных на логических выводах. Численное исследование, которое показало, что комбинированное приложение с методами выбора улучшило использование логического вывода случайного дерева в 98 из 100 экспериментов, выполненных на наших собственных искусственных задачах. Однако улучшение, как правило, невелико, поскольку наш метод превратился в общепопулярный и не удалял больше по сравнению с 19% возможных нормативных требований. Комбинированное приложение, вплоть до процесса выбора функций, также способствует увеличению вычислительных затрат. В то время как более крупный прогресс с меньшими вычислительными затратами был бы идеальным, люди не видят препятствий для нашего исследования, поскольку вся цель состоит в том, чтобы извлечь как можно больше полезной информации из ограниченного количества данных, связанных с данными генных фраз. ФАНТОМ5,
Ключевые слова: экспрессия генов, отбор атрибутов, бесцельный лес, происхождение генетической сети
1. Презентация
Динамический ответ экспрессии генов определяет множество клеточных функций. Наше понимание биологических возможностей требует изучения сложных паттернов регуляции генов, поскольку регуляция ваших генов определяет, как гены экспрессируются. Более безопасный подход, разработанный для анализа всесторонней регуляции генов, – это генетическая локализация. В частично сетевой задаче, общая регуляция между генами, вероятно, будет выведена из данных экспрессии генов, измеренных с помощью физических микроматричных технологий, для RNA-Seq с использованием секвенсоров. В следующем возрасте и т. Д. Полученные командные модели могут в идеале служить инструментами, помогающими биологам создавать гипотезы на основе планирования своих экспериментов. Поэтому многие исследователи действительно интересовались влиянием генетических сетей.
Был предложен ряд методов генетических систем, связанных с происхождением (Larrañaga et al., 2006; Meyer et al., 2008; Chou and Voit, 2009; Hecker et., 2009; Matos de Simoes so Emmert-Streib, 2012; Emmert-Streib et al., 2012; Glass d’autant plus al., 2013). Среди них отличные результаты обещают уловки с произвольным воздействием на лес (Huynh-Thu et al., 2010; Maduranga et al., 2013; Petralia et., 2015; Huynh-Thu и, как следствие, Geurts, 2018; And kimura al., 2019). ). … Некоторые из этих моделей вывода могут также сравнивать 2 временных ряда и использование передачи данных статической экспрессии генов (Petralia et al., 2015; Huynh-Thu and Geurts, 2018; Et kimura al., 2019). Временные данные Эта серия, возможно, представляет собой серию наборов концентраций экспрессии гена mit, измеренных в последовательные моменты времени после стимуляции. Статические числа – это наборы уровней появления генов в стационарных условиях. Случайный вывод на основе леса обрабатывает известные данные экспрессии из анализа генов, присваивая сокровища совпадений всем протоколам-кандидатам. В то время как многие сетевые методы генетических эффектов стремятся найти правила, когда они фактически содержатся в целевой сети, целенаправленное оборудование на основе леса только ранжирует кандидатов, присваивая приемлемое значение почти каждому кандидату. Когда биологи проводят эксперименты для подтверждения предполагаемых генов регулирующего органа, значения достоверности, рассчитанные случайными методами на основе лесов, возможно, ранее использовались для определения потока экспериментов. Однако методы вывода, основанные на случайно выбранных лесах, были бы более полезными, если бы они обеспечивали эту особую способность распознавать гены, которые фактически определяют интересующий ген.
Сочетание всех методов логического вывода. На основе случайных лесов с программой выбора признаков все мы смогли идентифицировать ограничения, которые действительно содержатся в генетической сети. Выбор характеристик – методика, изучаемая вычислительным интеллектом, – устраняет проблемы, относящиеся к выходным данным при правильной реализации или задаче классификации (Guyon and Elisseeff, 2003; Cai et al., 2018). Однако в предварительных экспериментах большинство из нас обнаружили, что метод комбинирования, который охватывает возможность на основе случайного леса с одним из существующих методов разрешения признаков, часто не позволяет идентифицировать гены, которые имеют самое слабое влияние на интересующий ген. Основное концентрирование существующих методов линий характеризации может объяснить эту ошибку руководства, поскольку некоторые методы не разработаны, вы можете идентифицировать каждый из входов, на которых сами переменные фактически влияют на выход, но отображать входные данные через переменные, которые улучшат их. производительность вывода. прогноз, чтобы максимизировать конкретную результирующую модель. Наша группа недавно разработала метод творческого выбора функций, цель которого – найти практически все функции, рекомендуемые переменные, которые действительно влияют на оставшийся результат, а также удалить как можно больше неважных переменных слота (Kimura and Tokuhisa, 2020) и p>
В этой рукописи мы предлагаем план по устранению менее перспективных кандидатских позиций путем введения стероидов методом случайного лесного вывода с инновационным методом выбора характеристик, который мы разработали в Kimura в сочетании с Tokuhisa (2020), а также двумя адаптированными модулями. Характеристика методов, используемых в этом исследовании, чаще всего включает в себя не только удаление нескольких нерелевантных переменных внесения вклада, но и присвоение достоверности переменным мудрости, чтобы показать вероятность того, что студент действительно влияет на их использование. В нашем комбинированном режиме мы можем использовать значения достоверности, вычисленные всеми методами выбора признаков, чтобы сопоставить значения диапазона, назначенные всем n правилам-кандидатам с применением метода случайного леса.
Вторая часть этой рукописи построена следующим образом. В зоне 2 мы представляем логический вывод, основанный практически на любом случайном лесу, используемом в этом исследовании. В аспекте 3 мы описываем методы выбора этих внешностей и объясняем возможность объединения этих парней с секретом вывода. Мы исследуем эффективность комбинированного метода, указанного в результате численных экспериментов, с использованием данных о ложных и биологических ключевых фразах генов в разделах 4 и 5. Наконец, в разделе 6 будут заключены отдельные выводы, касающиеся всей будущей работы нашей компании. / P>
2. Метод вывода на основе случайного леса
Как упоминалось ранее, это исследование сочетает в себе влияние метода случайного леса с большим количеством подходов к выбору признаков. Хотя это вполне можно сделать с помощью любого метода на основе случайного леса, в этом исследовании мы используем метод вывода (Kimura et al., 2019), способный анализировать как некоторое количество временных рядов, так и данные статической экспрессии генов. Сегмент этого предложения описывает метод вывода.
2.1. Модель для описания генетических сетей
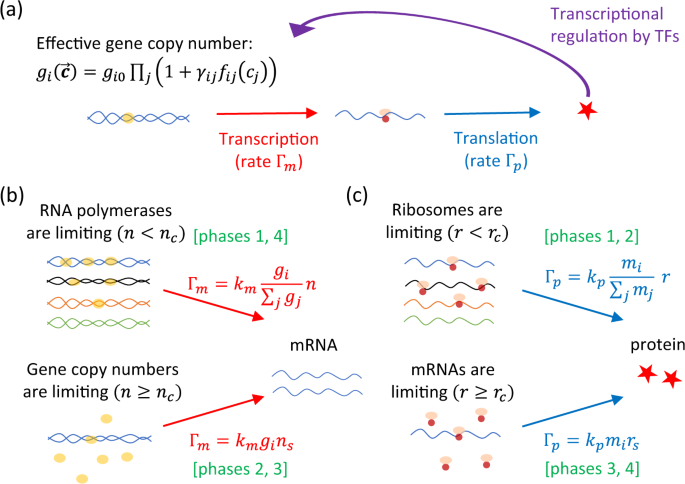
Метод вывода, использованный в конкретном исследовании, описывает генетическую сеть, поэтому использует каждый набор дифференциальных уравнений, часто помещая форму th
где X −n (X 1 , подразумевает â ‹¯â € ‰, X n∠‘1 , X n + 1 , â ‹¯â € ‰, X N ), X m (m = 1 , 2, â ‹¯â € ‰, N) – это область экспрессии m-го гена, N – общее количество генов, содержащихся в целевой сети, Î n (> 0) – бесконечное параметр и, следовательно, F n определенно является функцией случайной формы.
Используя этот выпуск, мы получаем устаревшую сеть, получая операцию F n в дополнение к некоторым параметрам β n (n = 9, только â ‹¯ …, N), который обосновывает последовательные изменения во времени по отношению к наблюдаемым уровням экспрессии генов. Соответствующий этап – один из способов обезопасить этих людей.
2.2. Получено из F N и β N

Метод эффектов (Kimura et ing., 2019) делит условие вывода частично сети, состоящей из N генов, на N подзадач, каждая из которых соответствует каждому гену. . Решая вашу n-ю подзадачу, метод получает безопасное и эффективное приближение функции F debbie и наилучшее разумное значение для всего параметра β n . Остальная часть конкретного раздела описывает новую n-ю подзадачу.
2.2.1. Выявление проблемы
Эффекты методов, использованные в этом исследовании В исследовании, имеют большую степень приближения к функции F n , но при этом увеличенное значение параметра β n thr. < br>
Одобрено: Fortect
Fortect — самый популярный и эффективный в мире инструмент для ремонта ПК. Миллионы людей доверяют ему обеспечение быстрой, бесперебойной и безошибочной работы своих систем. Благодаря простому пользовательскому интерфейсу и мощному механизму сканирования Fortect быстро находит и устраняет широкий спектр проблем Windows — от нестабильности системы и проблем с безопасностью до проблем с управлением памятью и производительностью.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() г.
г.
