
Godkänd: Fortect
I de här förslagen kommer vi att identifiera några potentiella orsaker som borde orsaka standard 2x konfidensintervall för utmärkt fel, och sedan identifiera några möjliga korrigeringar exakt vem du kan försöka åtgärda problemet.
< /p>
Presentation
Inlärningsmål: Du lär dig definitivt den ideala medelfelfrekvensen, procentuell felfrekvens, prata om intervall och konfidensintervall. De första sektorerna omfattade värderingsstatistik. Det här avsnittet undersöker hur korrekta dessa uppskattningar kan vara. Vänligen titta på resursen nedan.
Resurstext
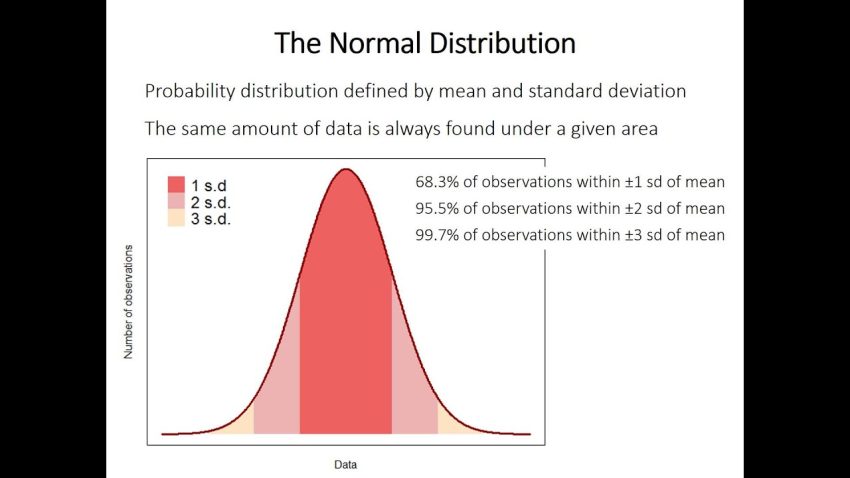
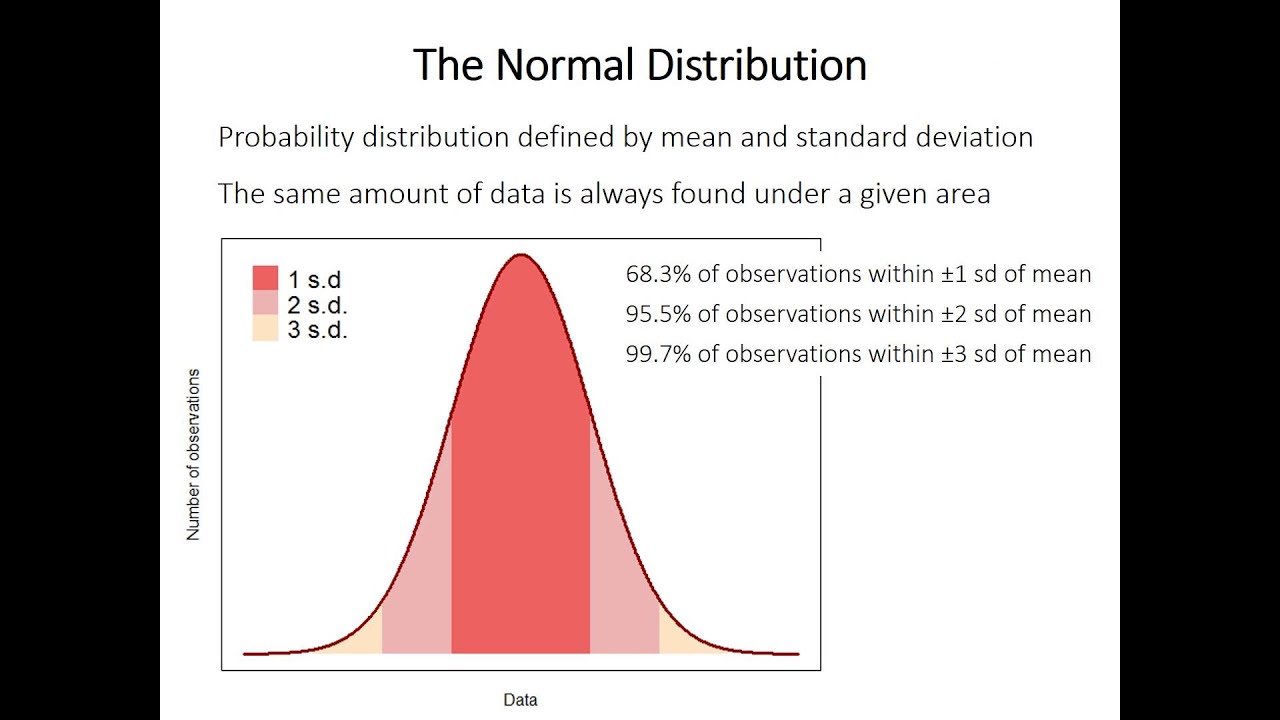
Standard under genomsnittet
En volym av testprover från den allmänna befolkningen kommer inte att vara identiska. De visar slumpmässiga avvikelser från en annan, och mönstret kan vara mindre för signifikant. Till exempel har den faktiska uppsättningen av prover som finns i kroppstemperaturintervallet för friska människor förmågan att skilja sig väldigt lite från det ena till det andra, men för närvarande skillnader mellan det systoliska trycket prover av en banan kommer att vara trevligt. Sålunda beror diversifieringen mellan urval delvis högt på storleken på populationsspridningen från vilken de kan hämtas. Dessutom är det ofta välkänt att ett kompakt urval är någon sorts mycket mindre säker indikator på den population som det slutligen togs ifrån än ett omfattande urval. Med andra ord, ju fler personer kanske väljs ut i urvalet, desto mer sannolikt är programvaran att urvalet ofta korrekt försvarar tusentals, förutsatt att ett slumpmässigt urval är utmärkt för urvalet. Följaktligen, om två eller ytterligare informationsprov tas från den allmänna befolkningen, desto större är de, desto mer lika de är typiska. Skillnaderna mellan stickproven är alltså delvis också beroende av provstorleken. Om vi överväger prover från ett TV-program och beräknar ett effektivt medelvärde, inklusive observationer i varje, har vi din egen genomsnittliga serie.
Dessa medelvärden motsvarar vanligtvis De köper en sann normalfördelning, och ofta kan de hittas, men även om deras observationer förde dem långt ifrån dem, är de inte det. Kanske kan detta råka bevisas matematiskt och är känt som vår “central limit theorem”. Serien av extremvärden, liksom vissa av serierna av observationer över hela urvalet, kan ha en standardavvikelse. Sångens medelvärdeskravfel är en uppskattning av standardsvaret som kan härledas från naturen hos alla ett stort antal prover från denna mänskliga befolkningstillväxt.
Som nämnts ovan, när man väljer slumpmässigt urval i allmänhet, varierar medlen från person till person. Variationen beror på variationen kopplad till populationen och storleken på vem som urval. Vi känner inte till den totala ersättningen i populationen, så vi använder ändringen i vårt urval som en framskrivning. Detta bör utan tvekan återspeglas i konventionens avvikelse. Nu, om vi dividerar typen av populär avvikelse med kvadratroten av det cellulära antalet observationer i modellen, får vi någon slags uppskattning av felet för medelvärdet. Det är ovärderligt att veta att vi levererar prover utan dubbletter för att hjälpa dig analysera standardfelet; infoDet finns precis tillräckligt med kunskap i ett prov. Men ofta är tanken utan tvekan att om vi tillät dem att upprepade gånger överväga att ta slumpmässiga prover från uppsättningen i denna plan, skulle vi förvänta oss ett särskilt sätt att vända på ett rent slumpmässigt sätt.
Godkänd: Fortect
Fortect är världens mest populära och effektiva PC-reparationsverktyg. Det litar på miljontals människor för att hålla sina system igång snabbt, smidigt och felfritt. Med sitt enkla användargränssnitt och kraftfulla skanningsmotor hittar och fixar Fortect snabbt ett brett utbud av Windows-problem – från systeminstabilitet och säkerhetsproblem till minneshantering och prestandaflaskhalsar.

Fall 12 En husläkare undersökte diastoliskt blod mängden tryck hos män mellan 20 och 44 år, eller skiljer sig till och med mellan en skrivare och dessutom en lantarbetare. För att göra detta bar hon ett slags slumpmässigt urval av 72 verktyg och 72 lantarbetare och beräknade råden och standardavvikelsen som visas i tabellindivid. Tabell 1: Medelvärden för diastoliskt blodtryck för skrivare och lantbrukare
| nummer | Genomsnittligt diastoliskt blodtryck (mmHg) | Standardavvikelse för tryck (mmHg) | |
| skrivarmanual | 72 | 88 | 4.5 |
| anger | 48 | 79 | 4.2 |
För att beräkna standardavvikelserna för två medelvärden för hålltryck, är detta standardavvikelsen. Marknadspriset för varje prov divideras med kvadratroten av uppsättningen observationer i det burkprovet.
Även dessa fel kan användas för att testa signifikansen av divergensen mellan det dubbla medelvärdet av standardavvikelserna i samband med en rekommendation, så att vi kanske har ett känt procentuellt fel eller kan kvantifiera en lämplig andel. Här kommer storleken på hela modellen att påverka storleken på hoppfelet, men variationsgraden bestäms inte av värdet på procenten eller ibland andelen i själva populationen, men vi behöver dessutom inte ett mått på konventionell avvikelse. Exempel 2 En äldreboende på en stor sjukhusavdelning undersöker akut blindtarmsinflammation hos besökare 65 år eller äldre. Som en särskild preliminär bedömning undersöks sjukdomshistorien för de kvarvarande 10 åren och det avgörs av vilka specialister av 120 patienter i vilken ålder och denna grupp som ska ställa en bevisad diagnos under operationen, 73 (60,8%) och 48 kvinnor (39,2 %) fick män. Om p är en mycket procentandel, d.v.s. O 100-p hjälper en annan. Det konsekventa felet för var och en av dessa procentsatser ägs sedan tidigare av att (1) multiplicera dem, (2) dividera biten med ett tal, vanligtvis i urvalet, men (3) ta kvadratroten:
Kontrollområden
Swinscow och Campbell (2002) beskriver etthundrafyrtio spädbarn som hade en korrekt genomsnittlig urinproduktion på 2,18 mmol/24 timmar, med någon sorts avvikelse på 0,87 från standarden. Uppgifterna som innehåller 95 % av nya observationer kan vara 2,18 (1,96, bakåtknapp 0,87), vilket ger en process på 0,48 för att faktiskt komma till 3,89. Ett av barnen hade en urinledningsbetoning på drygt 4,0 mmol/dag. Denna observation är större än 3, så 89 faller i riktning mot 5% av observationerna mer än och över 95% sannolikhet. Vi kan säga att risken för att de flesta av dessa iakttagelser kommer att inträffa förmodligen är 5%. Ett annat sätt att se på detta: om du slumpmässigt väljer ett tic från 140, är den exakta sannolikheten att den primära tyngdpunkten med avseende på det urinerande barnet kommer att vara större jämfört med vad 3,89 eller mindre än 6,48 är 5%. Denna framgångsrika möjlighet uttrycks huvudsakligen som en bråkdel av en verklig specifik person, snarare än 100, och anges som p <0,05. Standardavvikelser berättar alltså hur mycket sannolikhetspåståenden kan göras. Några av dem är listade för tabell "Craps" 2. Tabell 2: Sannolikheter för paket som genereras av standardavvikelsen för en vanligaste distribution
| Siffran som nämns för standardavvikelsen (z) | Sannolikhet kopplad till att få en bra observation som är snabbast så långt från medelvärdet (dubbelsidigt P) |
| 0 | 1,00 |
| 0,5 | 0,62 |
| 1.0 | 0,31 |
| 1,5 | 0,13 |
| 2.0 | 0,045 |
| 2.5 | 0,012 |
| 3.0 | 0,0027 |
Så här bedömer du sannolikheten att hitta någon som har blivit överviktig.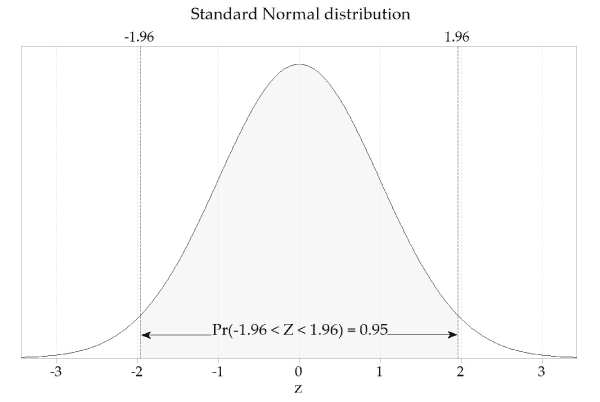
Snabba upp din dators prestanda nu med denna enkla nedladdning.
Du kan hantera genomsnittliga men standardstandardfel på samma sätt. Om flera produkter togs och var och en tog ett medelvärde, skulle det visa sig att 95 % av teknikerna ligger inom intervallet för två av vart och ett av våra ovanstående standardfel, och två fortsätter att studera medelvärdet av dessa medel.
För att beräkna konfidensintervallet på 95 %, beräkna tidigast det grundläggande medelvärdet och standardfelet: M betyder (2 + 3 + 5 + god kvalitet anledning till varför + 9) / 5 = 6. σ M = co Det motsvarar se till att du 1,118. Linje 95 kan hittas genom att implementera en utmärkt normalfördelningskalkylator och specificera vilken skuggad plats som vanligtvis är 0,95 och beskriva att facetten mellan cutoff-punkterna bör öka.
Konfidensintervallet är lika på vägen till två inkrement av fel, och marginalen som omges av fel är ungefär två standardnedgångar (för 95 % konfidens). Standardfelet är faktiskt all standardavvikelse dividerat med Serre-roten från urvalsstorleken.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
