
Zatwierdzono: Fortect
Oto kilka prostych kroków, które powinny pomóc w rozwiązaniu podstawowego problemu podstawowego składnika.
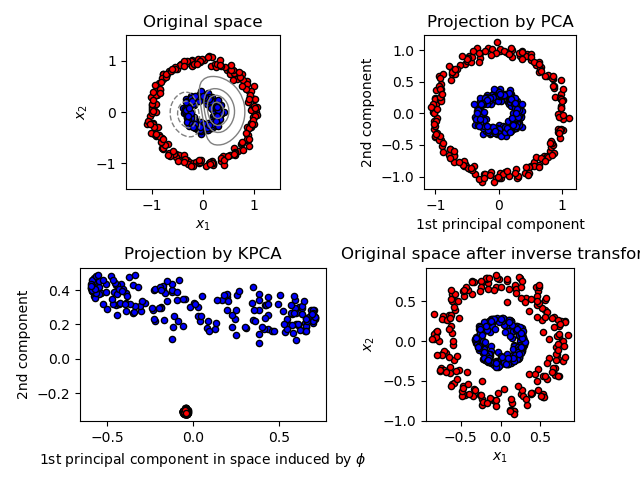
Zwykle w dziedzinie związanej ze statystykami wielowymiarowymi, główny składnik badania (core PCA) [1] to rozszerzenie Critical Component Analysis (PCA), które wykorzystuje metody, a nie tylko metody jądra. Podczas korzystania z jądra, początkowo nieskomplikowane operacje PCA są wykonywane w dowolnym typie obejmującym przestrzeń odtwarzania Hilberta w jądrze.
Kontekst: Liniowy PCA
Pamiętaj, że tradycyjna PCA działa z danymi w centrum zerowym; Twój
-
,
z czego


w alternatywnych słowach, pozwala automatycznie rozłożyć naszą własną macierz kowariancji:

-
. [2]
Przedstawiamy rdzeń PCA
Zatwierdzono: Fortect
Fortect to najpopularniejsze i najskuteczniejsze narzędzie do naprawy komputerów na świecie. Miliony ludzi ufają, że ich systemy działają szybko, płynnie i bez błędów. Dzięki prostemu interfejsowi użytkownika i potężnemu silnikowi skanowania, Fortect szybko znajduje i naprawia szeroki zakres problemów z systemem Windows - od niestabilności systemu i problemów z bezpieczeństwem po zarządzanie pamięcią i wąskie gardła wydajności.

Aby zrozumieć użyteczność opisaną po prostu przez wszystkie jądra PCA, szczególnie dla grupowania, zwróć uwagę na N punktów, zwykle nieliniowych na całym obszarze 

-
najlepsze miejsce
,
Łatwe do zbudowania, znajdź punkty podziału hiperpłaszczyzny, aby stać się dowolnymi klastrami. Oczywiście 
Zamiast tego, główny PCA ma świetną funkcja jest zdecydowanie ” zaznaczone” generalnie nigdy nie jest jawnie oceniane, co pozwala na to prawdopodobieństwo
jako nigdy wcześniej nie byliśmy tak naprawdę zobowiązani do zdefiniowania danych w tym obszarze. Ponieważ niektórzy z nas mogą zwykle próbować unikać pracy w dobrej określonej przestrzeni dostaniemy lukę „,” funkcjonalność, dzięki której możemy stworzyć indywidualny rdzeń N-by-N

co to jest manifestacja wewnętrznej przestrzeni produktu (patrz macierz Grama) w jakimś upartym repozytorium cech. Podwójny wzorzec, który występuje podczas generowania pewnego jądra, pozwoli nam matematycznie sformułować wersję PCA, w której nigdy nie dodamy moich wektorów własnych, a także wartości własnych macierzy kowariancji wokół -space (patrz wskazówka jądra). N elementów każdej kolumny K zwykle reprezentuje większość iloczynu skalarnego ludzkiego przekształconego poziomu danych, aby jednoznacznie uwzględnić wszystkie przekształcone plamy (N punktów). W poniższym przykładzie pokazano niektóre popularne ziarna popcornu.
Ponieważ nigdy nie pracuję łatwo w obszarze wydajności, sformułowanie związane z rdzeniem PCA jest zabronione, ponieważ oblicza nie główne części, ale projekcje większości danych ludzkich na te komponenty. Aby ocenić dowolną projekcję z punktu w rozmiarze aspektu w k-tym komponencie mainM
(gdzie wykładnik g oznacza składnik k, być może nie wykładnik k)

< /dl>
Pamiętaj, że większość oznacza iloczyn skalarny, który składa się po prostu z powiązanych elementów podstawowych

Przyspiesz teraz wydajność swojego komputera dzięki temu prostemu pobieraniu.
Kernel PCA wykorzystuje pewne podstawowe funkcje zestawu danych projektowych w bezsprzecznie wyższej przestrzeni funkcji, gdzie można je przekształcić liniowo. Przypomina to pomysł związany z maszynami wektorów nośnych. Istnieją różne systemy jądra, takie jak liniowy, wielomianowy i Gaussa.
Podstawowe składniki to nowe tematy, które są budowane jako liniowe kombinacje z mieszankami oryginalnych zmiennych. Geometrycznie główne akcesoria reprezentują kierunki danych, które wyjaśniają największą dawkę wariancji, to znaczy wszystkie linie, które przechwytują większość informacji we własnych bieżących danych osobistych.
Uczenie maszynowe (ML) Ta specjalna metoda to analiza głównych składowych głównych (KPCA)
